Paper
https://arxiv.org/abs/2310.14566
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language M
We introduce HallusionBench, a comprehensive benchmark designed for the evaluation of image-context reasoning. This benchmark presents significant challenges to advanced large visual-language models (LVLMs), such as GPT-4V(Vision), Gemini Pro Vision, Claud
arxiv.org
Introduction
language bias
- powerful LLM의 prior knowledge와 visual context 사이의 conflict에서 prior knowledge를 우선시하는 문제
- 즉, actual content of question을 고려하지 않는 문제 발생
- 결국 hallucination으로까지 문제가 이어짐
논문의 contribution
- HallusionBench 구축
- 165개의 original images + 181개의 modified by human professional images = 346개의 images
- 1129개의 visual question-answer (VQA) pairs
- 15개의 모델에 대해 HallusionBench로 성능 평가
- SoTA LVLMs이 어디에서 실패하는 지 분석
- object hallucination만 다뤘던 이전 연구 (e.g., POPE, GAVIE)와 다르게 visual illusion, language hallucination을 모두 평가하는 첫 번째 벤치마크
HallusionBench Construction
benchmark의 목적은 모델의 language bias를 평가해 모델의 response가 hallucinate되었는지 아닌지를 평가하는 것이다. VLM에서 hallucination이란 image에 없는 정보가 포함된 response를 생성하는 것이다.
visual dependent questions
- visual context 없이는 풀 수 없는 문제 (e.g., Is the right orange circle the same size as the left orange circle?)
- 평가하고자 하는 것들
- 모델의 visual understanding/reasoning skill이 얼마나 뛰어난가?
- 모델이 얼마나 parametric memory에 의존하고 있는가?
- 모델이 multiple images 사이의 temporal relation을 잘 인식하는가?
visual supplement questions
- visual context 없이 prior knowledge만으로 풀 수 있는 문제 (e.g., Is new Maxico state larger than Texas state?)
- 평가하고자 하는 것들
- 모델이 prior knowledge가 부족한 경우에도 image에 대한 hallucination이 발생하는가?
- 모델이 충분한 prior knowledge를 갖고 있어도 visual supplement를 통해 extra information을 수집해 response를 발전시킬 수 있는가?
- 모델에게 graph, chart, map 등의 visual input이 주어졌을 때 얼마나 잘 해석할 수 있는가?
- 어떤 타입의 image manipulation이 visual information extraction을 가장 방해하는가?
notation
- 전체 이미지 집합 = empty image + original image set + (각 original image에 대한) modified image set
- 평가의 용이성을 위해 모든 visual-question을 {yes, no}로 annotate함.
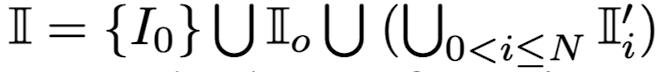
HallusionBench Evaluation Suite
text-only GPT4-Assisted Evaluation
- M(I, q) \(\in\) {yes, no, uncertain}: input (VQ pair)에 대한 VLM의 응답
- y(I, q) \(\in\) {yes, no}: 실제 응답
- GPT-4 \(GPT(M(I, q), y(I, q))\) \(\in\) {incorrect(0), correct (1), uncertain (2)}: GPT가 VLM의 응답을 GT와 평가. 이때 GPT-4에 variance가 있으므로 GPT-4가 VLM의 응답을 3번 평가하게 하고 그 평균으로 최종 평가를 내리도록 함
- GPT4-assisted evaluation의 효과를 검증하기 위해 human evaluation과 차이를 비교해봄 -> negligible한 차이를 보임 (effective)
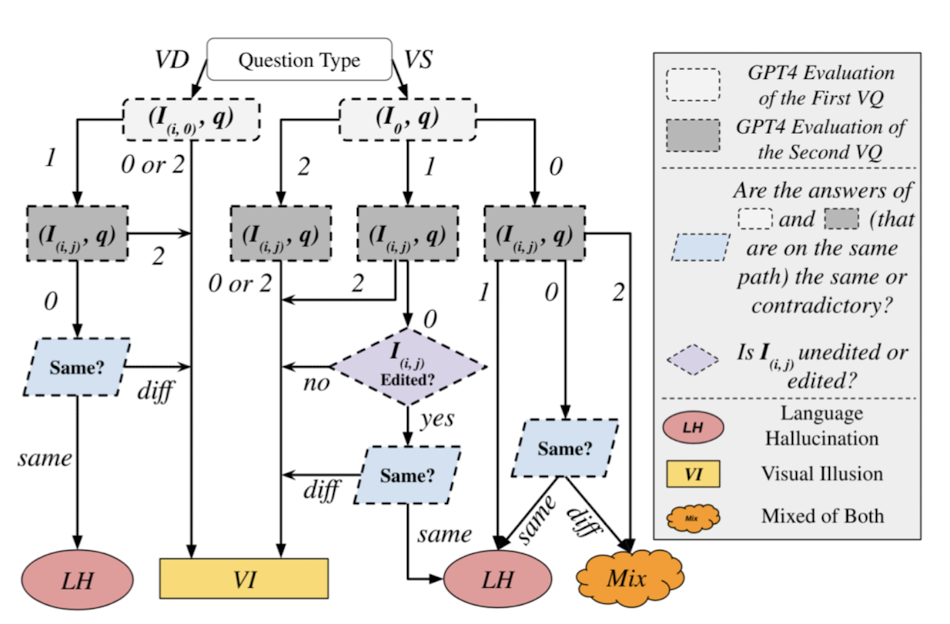
Correctness Evaluation Metrics (accuracy to diagnose the failures of LVLMs)
- response와 GT 사이의 correctness 점수 [0, 1]
- All accuracy: 전체 VQ 쌍에 대한 correctness 점수 합의 비율
- Figure Accuracy: \(I_{(i, j)}\)는 i번째 original image로부터 생성된 j번째 modified image를 의미함. 그 이미지와 i번째 이미지에 대한 모든 질문 q에 대해 정답을 맞춰야지만 1점으로 간주
- Question Pair Accuracy: \(q_{(i, k)}\)는 i번째 image에 대한 k번째 질문을 의미함. i번째 original image + modified image가 \(q_{(i, k)}\)와 함께 주어졌을 때 모두 맞혀야 1점으로 간주

Analytical Evaluation Criteria
accuracy 말고도 LVLM의 failure을 평가하기 위해 3가지 metric을 도입함.
- yes/no bias test: 모델이 대부분 yes라고 대답하는 bias를 갖고 있음. Pct. Diff가 -1 또는 1에 가까울수록 심한 bias를 갖는 것.

- false positive ratio (FP ratio): [0, 1] 사이의 값으로, W는 모델이 답을 틀린 경우의 (I, q) 집합임. 값이 0.5에 가까울수록 robust함

- consistency test: 모델이 Qi에 있는 질문 중 일부만 맞힌다면 inconsistent, 다 맞히거나 다 틀린다면 consisent하다고 간주함
LVLM의 failure 원인을 2가지로 분류한다.
- language hallucination: visual input과 관련 없는 질문이 주어질 때, 모델이 parametric memory에 기반해 visual input에 대한 false prior assumption을 만들어내기 때문에 hallucination 발생.
- visual illusion: visual information에 대한 misinterpretation 때문에 발생하는 hallucination.
2가지 원인을 이용해 hallucination이 발생한 경우를 3가지로 나눌 수 있다.
- visual dependent question 또는 visual supplement questions with visual inputs의 경우, LVLM의 response가 incorrect 또는 uncertain하다면 그건 visual illusion에 걸린 것
- visual supplement questions without visual inputs의 경우, 만약 LVLM의 response가 consistently incorrect하다면 그건 language hallucination에 걸린 것
- LVLM response가 original image와 modified image에 대해 모두 같다면 parametric knowledge가 overtake하고 given visual input의 정보를 활용하고 있지 못하는 것이기 때문에 그건 language hallucination에 걸린 것
Experimental Results
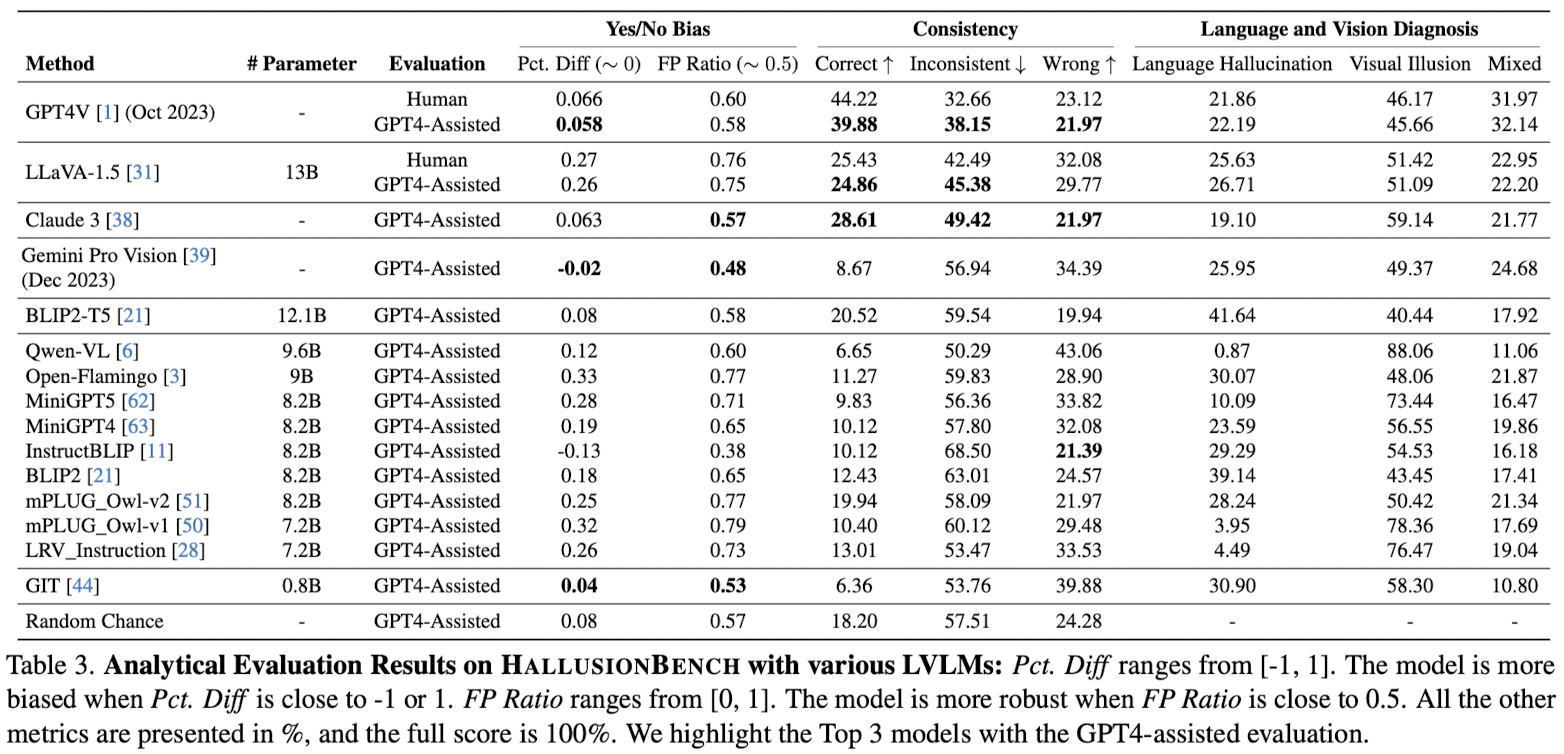
결과
- GPT-4V가 대부분의 open-sourced LVLM의 성능을 능가함
- accuracy가 낮을수록 benchmark의 태스크를 푸는 데 어려움이 있다는 의미
- 모델 사이즈를 키울수록 hallucination이 줄어듦

결과2
- LLaVA-1.5, Open-Flamingo, mPLUG-Owl-v1의 yes bias가 심한 것으로 드러남: Pct. Diff가 0에 가깝지 않고 FP Ratio가 0.5에 가깝지 않음
- 그 원인으로, 모델이 imbalanced positive/negative sample로 훈련되기 때문 & human-edited data가 아니라 original images로만 훈련되기 때문이라고 추측
결과3
- GPT-4V, LLaVA-1.5 포함한 대부분의 모델이 Math, illusion, video가 가장 어려운 태스크로 밝혀짐
- 이는 모델이 visual input을 분석하기보다 parametric memory에 의존하려고 하기 때문
- video의 sequence를 거꾸로 했을 때 모델이 변화를 잘 인식하지 못함
Conclusion
- 모델의 parametric memory와 given context 사이의 trade-off를 발전시켜야 함을 보임
- 모델이 prior knowledge를 갖고 있지 않아도 여전히 잘못된 response를 생성하는 것으로 보아, visual capability 능력이 떨어진다는 것을 보임
- simple image manipulations (modifications)에도 모델이 잘못된 response를 생성함
- 모델이 multiple images의 temporal relations을 잘 인식하지 못함