논문 리뷰 💬 [INSIDE: LLMs' Internal States Retain The Power of Hallucination Detection]
📚 Paper
https://arxiv.org/pdf/2402.03744
Abstract
기존의 hallucination detection은 logit-level uncertainty estimation(MLE 이용) 또는 language-level self-consistency evalution(같은 query에 대해 생성된 여러 개의 output을 n-gram based method를 사용해 비교해서 LLM consistency를 측정하는 방법)을 사용했는데, 이는 semantic information을 잘 보존하지 못한다는 문제가 있다.
본 논문은 LLM의 internal states가 dense semantic information을 보존하고 있다고 하여, INternal States for hallucInation DEtection(INSIDE) 프레임워크를 제시한다. 또한 EigenScore metric을 사용해서 응답의 self-consistency를 보다 잘 평가할 수 있다. 응답의 covariate matrix의 eigenvalue는 dense embedding space에서 응답들의 semantic consistency를 나타내는 지표이기 때문이다. 더 나아가, overconfident hallucination을 막기 위해 extreme activation feature는 truncate하는 feature clipping을 사용한다.
Introduction
hallucination을 정확하게 detect하고 hallucination이 일어나면 LLM으로 하여금 응답하는 것을 거부하도록 하는 것이 중요하다.
token-to-sentence uncertainty derivation은 불분명하고 복잡한 방법이다. 따라서, 하나의 query에 대해 여러 개의 response를 생성하여 응답들 사이의 consistency인 self-consistency를 평가해 hallucination를 detect하는 방법을 제시한다. 그러나, 이런 post-hoc(임상실험 후 관찰된) semantic measurement는 logical consistency를 모델링하기에는 부족하다. => logit-level or langauge-level uncertainty estimation
따라서, 위와 같은 logit-level or language-level uncertainty estimation 방법 말고, 본 논문에서는 LLM의 internal states를 사용해 hallucination detection할 수 있다고 한다. 본 방법론의 intuition은, LLM은 그 internal states에 전체 sentence에 대한 highly-concentrated semantic information을 보존하고 있다는 것이다. 이 점이 hallucinated response를 직접적으로 탐지할 수 있도록 한다.
본 논문의 point는 크게 네 가지로 정리할 수 있다.
- hallucination detection을 하기 위해 LLM의 internal states를 사용한 INSIDE framework를 제시한다.
- embedding space에서의 semantic consistency를 측정하기 위해 EigenScore metric을 구축하고, EigenScore가 sentence embedding space에서 differential entropy를 나타냄을 증명한다.
- feature space에서 extreme activation을 truncate하기 위해 feature clipping을 도입한다. 이는 overconfident hallucination을 줄이는 방법이다.
- several QA benchmark에 대해 SOTA hallucination detection performance를 갱신했다.

Background on Hallucination Detection
(특히 QA downstream task가 민감한) knowledge hallucination detection을 위주로 설명한다.
Eqn. (1)은 Maximum Softmax Probability(MSP)이다. 즉, 입력 시퀀스 x와 LLM의 파라미터 세타가 주어졌을 때 출력 시퀀스 y = [y1, y2, y3...yT]를 생성할 확률이다. 출력 시퀀스의 길이인 T로 joint probability를 normalize할 수 있다. -> 이 확률을 이용해 uncertainty measure of prediction / classification result의 confidence level을 나타낼 수 있다. (perplexity)
그러나, 시퀀스에는 중요한 부분(토큰)이 있기 때문에 모든 토큰에 대한 generate probability를 곱한 것으로 sentence의 semantics와 sentence uncertainty를 정의하는 데에는 무리가 있다.
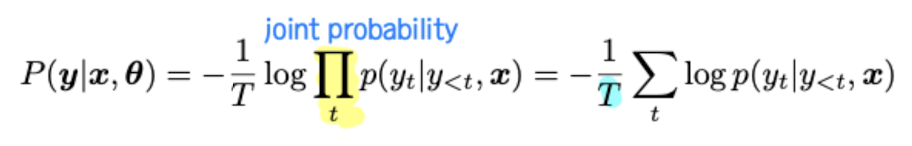
따라서 하나의 query x에 대한 K개의 output = y = [y^1, y^2, ...y^K]을 활용하고자 했다. 이때 K개의 response는 top-k/top-p sampling을 사용해서 얻을 수 있다. Eqn. (2)는 Length Normalized Entropy 식이다. 각각의 output y는 Ty 길이의 시퀀스이다. uncertain할수록 entropy가 높아지며 모델이 응답에 대해 확신이 없다는 의미이기에 hallucination된다고 판단할 수 있다. Eqn. (2)가 Eqn. (1)보다 성능이 좋다.

또한, "만약 LLM은 input context를 알고 정답에 대한 확신이 있다면, similar output을 생성한다"고 가정한다. 이 가정을 이용한 semantic consistency metric이 Lexical Similarity다. ROUGE-L을 사용해 정의된 similarity를 이용해 generated response의 유사도를 측정한다. 이때, ROUGE-L은 LCS(Longest Common Sequence)의 길이를 사용하여 recall과 precision을 계산하고 순서와 위치를 고려한다. (recall = LCS의 길이 / label의 n-gram 수, precision = LCS의 길이 / predicted output의 n-gram 수)


Method
Hallucination Detection by EigenScore
dense semantic information을 더 잘 뽑아내기 위해 sentence embedding space에서 semantic divergence를 측정하기를 제안한다. t번째 출력 토큰을 yt라고 하고 l번째 layer에 있는 hidden embedding representation을 h_t^l이라고 한다. 이때 hidden state는 d-dimension이다. 일반적으로 token embedding은 Eqn. (3)와 같이 출력 시퀀스의 모든 토큰들의 hidden embedding의 평균으로 나타낼 수 있다. 또는 Eqn. (4)와 같이 sentence embedding z으로 마지막 토큰의 embedding을 사용할 수 있다.
그러나 본 논문에서는 middle layer에 있는 마지막 토큰의 hidden embedding을 sentence embedding z로 사용한다고 한다. sentence의 마지막 토큰이 문장의 semantic information을 효과적으로 capture하기 때문이다. (일반적으로 train 때는 주어진 입력 시퀀스가 LLM을 통과하면 출력 시퀀스가 한 번에 나오는 구조다. 즉 다음 출력 토큰을 생성할 때 이전 단계에서 생성된 토큰이 아니라 golden 토큰이 주어진다는 얘기다.)
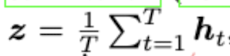

Z의 각 열은 똑같은 query에 대해 생성된 K개의 response hidden embedding, 즉 z으로 구성된 matrix이다. J는 centering matrix으로, 벡터에 곱해지면 그 벡터의 각 구성 요소에서 구성 요소들의 평균을 빼는 효과를 준다. Eqn. (5)의 시그마는 K responses hidden embeddings의 covariance matrix으로, K 문장 사이의 관계를 capture한다.

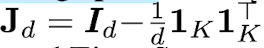

EigenScore는 Eqn. (6)과 같이 covariance matrix의 logDet를 이용해 정의된다. full rank라는 것은 행렬의 모든 열이 선형 독립이라는 것을 의미한다. 즉, 행렬의 다른 열들을 어떻게 조합해도 행렬에 있는 하나의 열을 나타낼 수 없다는 의미다. full rank하도록 만들기 위해 alpha x K짜리 identity matrix를 covariance matrix에 더해준다.
이때, det(X)를 구하는 것은 X의 eigenvalue의 곱을 구하는 것과 같기 때문에 Eqn. (6)을 Eqn. (7)과 같이 고쳐쓸 수 있다. log의 성질을 이용해 product를 sigma로 바꿔줄 수 있다. 즉 Eqn. (7)이 의미하는 바는, 어떤 하나의 query에 대한 response의 hallucination degree를 / response sequences vector representation 행렬의 covariance matrix의 average logarithm of the eigenvalue로 구할 수 있다는 것이다.
만약 LLM이 답변에 있어 confident하다면 대부분의 eigenvalue는 0이 될 것이다. 이는 response vector representation이 유사하다는 의미다. 따라서 logarithm eigenvalue의 합도 작아지기 때문에 hallucination degree는 낮을 것이다.
만약 LLM이 답변에 있어 indecisive하고 hallucinating content를 포함하고 있다면 생성된 여러 개의 답변은 서로 다를 것이고, 그 response vector representation이 다를 것이기 때문에 eigenvalue는 상당한 값을 가질 것이다. 따라서 logarithm eigenvalue의 합도 커지기 때문에 hallucination degree는 클 것이다.

그렇다면 왜 EigenScore가 hallucination detection에 대한 좋은 metric일까? 그 이유는 바로 LogDet of covariance matrix가 sentence embedding space에서 differential entropy를 나타내기 때문이다.(EigenScore의 값이 낮으면 그만큼 sentence embedding들이 비슷하다는 뜻 -> LLM이 response generation에 있어 자신이 있다! certain하다!) differntial entropy란 continuous space에서의 entropy로, Eqn. (8)과 같이 discrete probability p(x)를 density function f(x)로 대체한 식이다. 이때 differential entropy는 Eqn. (9)처럼도 나타낼 수 있고, 따라서 sentence embedding space에서의 differential entropy(즉 얼마나 randomness가 높은지, 불순하지)는 covariance matrix의 logarithm eigenvalue의 합에 의해 결정된다. 따라서, EigenScore는 dense embedding space에서 semantic divergence인 entropy를 수치화할 수 있기 때문에, logit or language based uncertainty estimation보다 semantic information / divergence를 더 잘 capture할 수 있다.
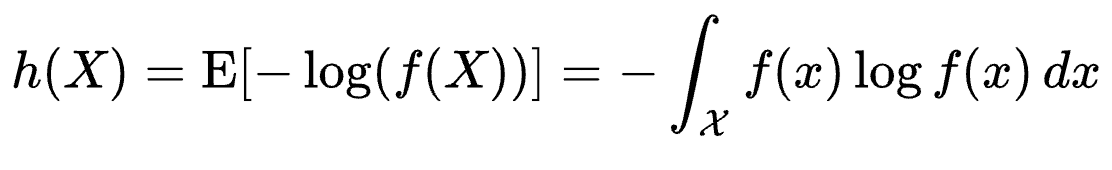
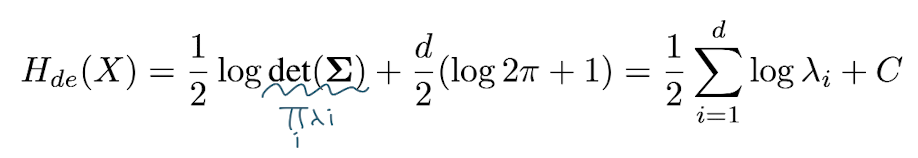
Test Time Feature Clipping
LLM은 overconfident hallucination에 빠질 수 있다. overconfident hallucination, LLM은 fluent, human-like text를 generate하도록 훈련됐고, 이러한 유창한 generation ability는 nonsensical 또는 fictional한 내용에 대해서도 convincing, detailed text를 생성할 수 있도록 한다. 따라서 충분한 background가 없음에도 LLM은 답을 생성하게 되는데, 이를 overconfident hallucination이라고 한다.
이때 실험에서 문제가 되는 것은, 본 논문은 생성된 K개의 답변들이 self-consistent하면 hallucinated되지 않았다고 가정하고 있지만, self-consistent(overconfident) hallucination은 hallucination이 발생했음에도 어쨌든 답변들이 self-consistent하기 때문에 실험에 부정적인 영향을 줄 수 있다는 것이다. 따라서 feature clipping을 사용한다.
Figure 1은 LLaMA-7B의 penultimate layer의 neuron에 대한 그래프이다. penultimate layer는 출력층 바로 이전 층으로, 고차원의 특징들이 집약되어 있다. (a)는 임의의 sampled token에 대해 penultimate layer의 hidden neuron activation level을 나타낸다. (b)는 numerous token에 대한 penultimate layer neuron activations들을 randomly sampled한 것으로, 대부분이 잘 activated된 것을 확인할 수 있다. 이를 통해 얻을 수 있는 직관은, LLM의 penultimate layer는 매우 많은 feature를 나타내고 capture한다는 것이고, 이는 곧 overconfident로 이어질 수 있다는 것이다.

feature clipping은 Eqn. (10)으로, h는 LLM penultimate layer에서의 hidden embedding의 특징을 나타낸다. h_min과 h_max는 truncate할 activation의 threshold이다. 즉, penultimate layer에서 과도하게, 혹은 과소하게 반응을 하는 activation neuron이 있다면 이를 truncate해버리는 것이다. 이때 memory bank를 사용해서 N개의 token embedding만을 저장할 수 있도록 하는데, percentile을 설정해서 memory bank의 상위 p%와 하위 p%를 abnormal feature로 인식해 truncate하는 것이다. 이를 통해 overconfident hallucination을 줄일 수 있다고 한다.

Experiments
Experimental Setup
- datasets: QA dataset을 중점적으로 사용, CoQA, SQuAD, TriviaQA, NQ dataset을 사용했다.
- models: LLaMA-7B, LLaMA-13B, OPT-6.7B를 사용했다.
- evaluation metrics: hallucination detection ability를 모델로 하여금 generation이 옳은 것인지 hallucinated된 것인지를 판단하는 능력으로 정의했다. 즉, binary classification 테스크라는 것이다. 따라서 AUROC와 PCC(Pearson Correlation Coefficient)를 평가 지표로 사용했다. 두 지표 모두 값이 높을수록 성능이 좋음을 의미한다.
- baselines: uncertainty-based method인 perplexity, length-normalized entropy(LN-Entropy), lexical similarity, energy score를 comparison method로 사용한다.
- correctness measure: generation이 옳은 것인지 hallucinated된 것인지를 판단하는 방법으로, ROUGE-L과 semantic similarity를 사용한다. generated text embedding과 golden embedding을 비교해서 ROUGE-L이 0.5(designated threshold) 이상이면 generation은 옳은 것이다. 마찬가지로 generated text embedding과 golden embedding을 비교해서 cosine similarity가 0.9 이상이면 generation을 옳은 것으로 간주한다.
- implementation details
- temperature(trade-off between safety and diversity): 0.5
- top-p: 0.99
- top-k: 5
- K = 10
- alpha = 0.001
- memory bank N = 3000
- last token embedding of the sentence in the middle layer
- 즉, correctness measure를 사용해 datasets를 labeling하고, baseline과 eigenscore를 이용해 hallucination detection(0/1)을 한 뒤, 그 결과를 evaluation metrics를 이용해 평가한다.
Main Results
- effectiveness of EigenScore
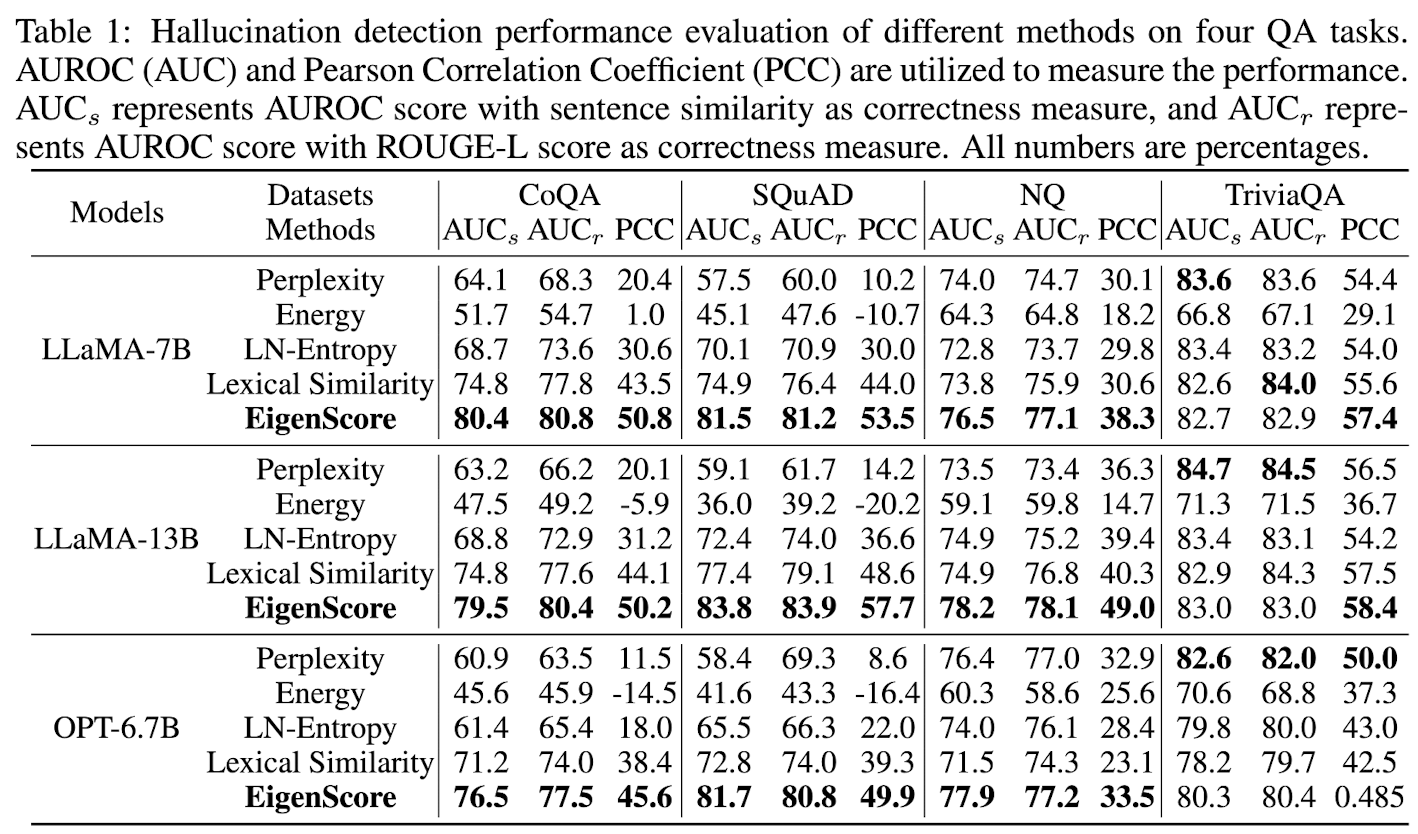
- effectiveness of feature clipping: feature clipping을 통해 overconfident hallucination으로 모델이 잘못된 예측(hallucination인데 hallucination이 아니라고 예측하는 경우)을 하는 경우가 줄어든다.
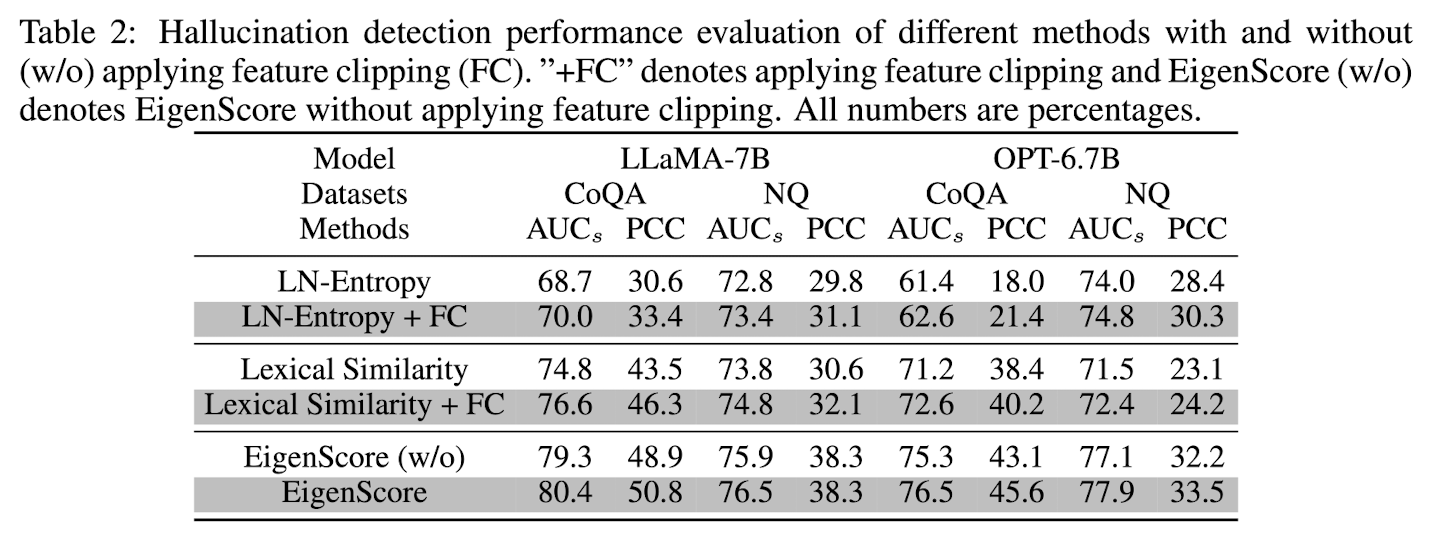
Ablation Studies
- number of generations(control K): {5, 10, 15, 20, 30, 40}의 범위에서 K를 골라 실험했다. Figure 2의 (a)를 보면 K = 20이내에서 최적의 K를 찾을 수 있음을 알 수 있다.
- how EigenScore performs with different sentence embedding: 본 실험에선 중간층의 last token embedding을 sentence embedding으로 사용했지만, Figure 2의 (b)에서는 다양한 층의 sentence embedding으로 했을 때의 evaluation performance를 보이고 있다. 중간층에서 semantic information을 많이 보유하고 있음을 알 수 있다. 오렌지 선은 middle layer의 last token embedding을 사용했을 때의 성능, 회색 선은 마지막 layer의 averaged token embedding을 사용했을 때의 성능으로 성능차가 꽤 나는 것을 확인할 수 있다.
- sensitivity to correctness measures: ROUGE-L과 sentence similarity와 같은 correctness measure의 threshold를 어떻게 설정하느냐도 final hallucination detection performance에 영향을 끼친다. Table 3를 보면 그 영향을 알 수 있다.


Related Work
- reliability evaluation of LLMs: LLM의 unreliable generation에 대해 uncertainty based metric (predictive confidence or entropy of the output token)와 consistency based methods (hypothesized that LLMs tend to generate logically inconsistent responses to the same question when they are indecisive and hallucinating contents)가 많이 사용되고 있다.
- eigenvalue as divergence measure: 행렬의 eigenvalue는 data의 varaince / divergence를 나타낸다. eigenvalue가 작을수록 variance가 낮은 것이므로 sentence embedding 사이의 semantic consistency가 높다고 할 수 있다.
Conclusion
hallucination detection은 reliability of LLM-based AI system의 성능을 높이는 데에 매우 중요하다. INSIDE framework를 제시하는데, 이는 LLM internal states가 semantic information을 담고 있음을 이용한다. 이때 hallucination degree를 구하는 데 EigenScore를 사용하는데, 이는 dense embedding space에서 여러 개의 generation의 semantic consistency를 수치화한다. 또한 self-consistent(overconfident) hallucination을 막기 위해 feature clipping을 사용해 extreme activated features를 truncate한다.
Appendix
baseline과 EigenScore의 threshold, 즉 어떤 값 이상이어야 hallucination이라고 판단하고 어떤 값 이하이어야 옳은 generation이라고 판단할까? 그 기준은 Eqn. (11)을 최대화하는 threshold로 정한다. 이때 TPR = True Positive Rate = Recall = TP / TP + FN, FPR = False Positive Rate = FP / FP + TN이다. G-Mean을 사용해서 구한 metric별 optimal threshold는, EigenScore = -1.74, perplexity = 0.535, LN-Entropy = 0.153, Lexical Similarity = 0.489일 때다. (이때 EigenScore, perplexity, LN-Entropy는 값이 낮을수록 좋고, Lexical Similarity는 값이 높을수록 좋다.)
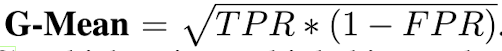
Case Study
초록색은 correct answer, 빨간색은 hallucinated answer이다. 체크 표시는 metric이 hallucination detection을 잘 했음을, x표시는 metric이 hallucination detection 잘 못 했음을 나타낸다.
case 1: correct answer이므로 perplexity, LN-Entropy, EigenScore의 값은 각각의 threshold보다 낮게, lexical similarity는 threshold보다 높아야 한다. 모두 체크 표시이므로 모든 method가 hallucination detection에 성공했다.

case 2: correct answer인데, Eigenscore만 threshold보다 낮아 hallucination detection에 성공했다. -> EigenScore의 outperformance!

Model Generation with many and few outliers (extreme features)
extreme features란 과도하게 activated된 neuron을 의미한다. 즉, memory bank에서 truncate되는 feature of hidden representation을 의미한다. extreme features가 많으면 consistent hallucination output이 발생하고 extreme features가 적으면 diverse hallucination output이 발생한다.


그러나 feature clipping(노란색)을 적용하면 EigenScore가 threshold보다 높아 hallucination detection에 성공함을 보였다.