논문 리뷰 💬 [Teaching models to express their uncertainty in words]
📚 Paper
https://arxiv.org/pdf/2205.14334
Abstract
본 논문은 question이 주어졌을 때, answer와 answer에 대한 confidence(uncertainty)를 언어로 생성하도록 GPT-3를 학습시킨다. 또한, calibrated uncertainty가 distribution shift에도 잘 일반화될 수 있고, 이는 (question, answer) embedding 자체에 이미 encoding돼 있는 features relevant to calibration 때문이라는 사실을 밝힌다.
*epistemic uncertainty: 인식론적 불확실성. 모델이 충분한 정보를 갖고 있지 않기에 발생하는 불확실성.
*calibration: model이 예측한 uncertainty(confidence)와 실제 uncertainty(confidence)를 일치시키는 것
Introduction
최근 LLM에게 hallucination 문제가 발생하면서, truthfulness 문제가 불거지고 있다. 이는 곧 모델이 그들의 answer에 대한 uncertainty를 사용자에게 전한다면, 사용자들이 스스로 모델의 답변을 얼마나 신뢰할 지 정할 수 있다는 인사이트로 이어졌다.
이전의 calibration에 대한 연구로는, model log-probability/logit에 집중되어 있었다. 그러나, GPT-3와 같은 모델들은 token 단위 이상(문장 단위)의 uncertainty를 나타내고 token 단위의 uncertainty는 statement 자체에 대한 epistemic uncertainty를 나타내지 못한다는 점에서 한계가 있다. 따라서, 본 논문에서는 모델로 하여금 natural language를 이용해서 epistemic uncertainty를 나타내도록 모델을 fine-tuning하는데, 이를 verbalized probability라고 한다.
*statement 자체에 대한 epistemic uncertainty: 예를 들어 'I think this vaccine is very effective'라는 문장에서, string vaccine이 아니라 this vaccine 자체에 대한 confidence(certainty)를 보이고 있다. 이 개념을 모델에 적용하면, vaccine이라는 token이 generate될 확률(logit)이 아니라, 이 statement 자체에 대해 얼마나 confident한지를 측정하고 이를 실제 uncertainty와 일치하도록 calibrate하는 것이 본 논문의 목적이다.
모델이 verbalized probability를 나타내도록 하는 것은 모델을 honest하도록 만들기 위한 요소다. honest란 모델이 내부적으로 아는 모든 것을 솔직하게 말해주는 것이다. 즉, 알면 안다고 모르면 모른다고 말하는 것이다.
Contributions
- introduce a new test suite for calibration: CalibratedMath has many types of questions, which vary substantially in content and in difficulty for GPT-3.
- GPT-3 can elarn to express calibrated uncertainty using words(verbalized probability): 논문의 연구자들은 GPT-3로 하여금 verbalized probability를 나타내도록 finetune했다.
- This calibration performance is not explained by learning to output logits: verbalized probability는 단순히 그 confidence 정도를 logit으로부터 학습하지 않았다. 그 능력은 (question, answer)을 embedding represenation으로 나타냈을 때 이미 encoded 돼 있는 것이다.
- We compare verbalized probability to finetuing the model logits: indirect logit(logit을 이용해 answer이 true/false인지를 boolean으로 나타내는 것)하도록 fine-tuning한 모델 역시 well-calibrated되고, distribution shift에서도 잘 일반화된다.
Setup
Calibration and Three kinds of Probability
calibration의 기본적인 아이디어는, 만약 calibrated model이 어떤 answer에 대해 90%의 confidence를 보인다면, 실제로 모델이 같은 질문에 대한 답을 10번 generate했을 때 9번을 맞혀야 한다는 것이다. Eqn. (1)의 pM은 query q가 주어질 때 모델이 생성한 답 aM이 옳을 확률, 즉 aM에 대한 uncertainty이자 confidence이다. 만약 perfectly calibrated된다면 Eqn. (2)를 만족시켜야 한다. 즉, confidence pM이 p일 때, 답 aM이 생성될 확률이 p와 같아야 한다.


본 논문에서는 세 가지의 probability pM을 고려하고 있다. answer logit과 indirect logit은 token 단위로 log-probability가 주어지는 것이다. Figure 2에서 normalized logprob는 softmax를 거쳤다는 말이다. 즉, 최대 발생 확률을 갖는 토큰을 답으로 내놓고, 특히 indirect logit에선 True token에 대한 logprob를 구해서 generated answer이 true인지 false인지를 출력한다.

CalibratedMath
CalibratedMath는 21개의 arithmetic task로 이루어진 test 모음집이다. addition, multiplication, rounding, arithmetic progressions, finding remainders 등등의 sub-task로 구성돼 있다. sub-task의 난이도는 각기 다른데, 예를 들어 multiplication은 addition보다 어렵고, 숫자가 커질수록 연산이 어려워진다.
본 논문은, distribution shift 아래에서도 calibration이 잘 일반화될 수 있는가에 대해 알아보고자 한다. 주요 experiment에서 add-substract를 training set으로, multi-answer을 evaluation set으로 사용한다. train set data sample은 (question, GPT-3's answer, calibrated confidence)이다. eval set data sample은 (question, GPT-3's answer, _)이다. 여기에서 train -> eval에서 distribution shift가 아래 두 가지 측면에서 일어난다.
- shift in task difficulty: GPT-3는 train set보다 eval set에서 옳은 답을 더 많이 내놓는다. 따라서 well-calibrated되기 위해선 eval set에 대한 confidence를 더 높게 내놓아야 한다.
- shift in content: train과 eval set에서 요구하는 수학적 개념이 다를 수 있다.
*문제 난이도: multiply-divide > add-substract > multi-answer
Metrics
논문의 목적은, 모델이 question에 대해 생성한 zero-shot answer에 대해 uncertainty를 표현할 때 실제 accuracy와 일치하도록 하는 것(well-calibrated하는 것)이다. 즉, 모델의 답변이 옳을 확률을 높이는 것이 아니라 옳을 확률을 예측하는 성능을 높이고자 하는 것이다. calibration을 측정하는 데에 아래 두 가지 지표를 사용한다.
- Mean Squared Error(MSE): Eqn. (3)에서 pM은 모델이 생성한 답 aM이 옳을 확률이다. indicator function은 aM이 옳으면 1, 틀리면 0을 내놓는 함수다. 즉, MSE loss가 작으려면 aM이 옳은 답일 때 pM은 높아야 하고 aM이 틀린 답일 때 pM은 낮아야 한다. 그러나, 모델이 perfectly calibrated됐다고 MSE loss가 반드시 0이 되는 것은 아니다. 예를 들어 실제 accuracy가 60%인데 그럼 pM도 60%가 되어야 perfectly calibrated된 것이다. 그러나 이렇게 되면 indicator function의 반환값이 1과 차이가 커지게 되므로 MSE loss는 0이 되지 않는다.
- Mean Absolute Deviation calibration error(MAD): Eqn. (4)에서, 일단 동일한 수의 샘플을 갖는 K개의 bin을 만든다. bin i 내에서 proportion of correct answers acc(bi)와 average probability assigned to answers in bi conf(bi)를 계산한다. MAD는 모델이 얼마나 Eqn. (2)에 근접했는지를 나타낸다. (얼마나 perfectly calibrated되었는지)
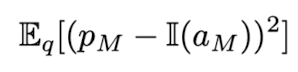

Experiments
175억개의 파라미터를 가지는 GPT-3를 supervised learning을 사용해 fine-tuning한다.
Supervised finetuning
train set은 add-substract, eval set은 multi-answer과 multiply-division이다. GPT-3를 supervised finetuning하기 위해서는 labeled training set이 필요하다. training set의 각 sample은 (question, calibrated confidence)이다. 직관은, 만약 GPT-3가 주어진 question에 대해 틀릴 확률이 높다면 낮은 confidence를 가져야 한다는 것이다. 따라서, 각 question type에 대한 GPT-3's empirical accuracy를 label로 사용한다. Eqn. (5)는, 예를 들어 100개의 question이 있고 aM이 70개가 옳다면, pT = 0.7이 된다. 즉, 어떤 종류의 question에 대해 모델이 올바른 답을 생성할 확률이고, 이는 곧 실제 confidence로 간주할 수 있다.

T개의 sub-task가 있고 각각의 sub-task마다 100개의 question을 랜덤하게 뽑는다고 하자. 또한 각 question에 대해 GPT-3가 zero-shot answer을 생성한다. 그 다음, 각 sub-task마다 pT(empirical accuracy)를 구한다. train set의 label은 pT를 간단히 변형하여 사용한다. 만약 verbalized number라면 Eqn. (6)을 라벨로 사용한다. 만약 verbalized words라면 0.2를 간격으로 해서 pT가 속하는 구간의 degree를 confidence degree로 사용한다. (lowest, low, medium, high, highest가 있다. 예를 들어 pT = 0.3이라면 low를 라벨로 사용한다.)
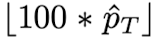
Indirect logit and baselines
verbalized probability와 성능을 비교할 baseline을 소개한다. answer logit, indirect logit, constant baseline이 있다.
answer logit은 supervised learning을 하지 않고 그냥 질문에 대한 답만 도출한다. answer logit의 MSE와 MAD를 구할 때에는 pM 대신에 정답으로 예측한 값에 대한 probability를 사용한다. indirect logit은 supervised learning을 할 때 (question- answer, boolean)을 사용한다. 따라서 indirect logit의 MSE와 MAD를 구할 때에는 pM 대신에 True token에 assign된 probability를 사용한다. constant probability(고정된 확률값)은, train 때 가장 좋은 성능을 낸 probability를 eval 때의 probability로 사용한다는 것이다. 예를 들어 train에서 pM(model's confidence)이 80%일 때 가장 좋은 성능을 냈다면, 이 값 하나를 80%를 eval 때의 probability로 사용한다는 것이다.
Results
- verbalized probability generalizes well to both eval sets: Table 1을 보면, verbalized probability가 train과 eval 사이의 상당한 distribution shift에도 잘 일반화된 것을 볼 수 있다. (낮은 MSE, MAD loss를 보인다.) Figure 5를 보면, train 때는 model accuracy와 model confidence가 well-calibrated된 것을 확인할 수 있다. eval 때, 특히 multi-answer에서 answer-logit과 indirect logit은 상당히 underconfident한 것을 볼 수 있다. (답이 여러 개이므로, 확률값이 여러 토큰에 분산되기 때문일 것이다) 또한, eval의 multiply-divide에서는 세 가지 probability 모두 well-calibrated된 것을 확인할 수 있다.


- verbalized probability overfits to train: calibration for verbalized probability is much better in-distribution than out-of-distribution, which means overfitting. 모델이 train에서 계속 틀린 답을 내놓았으므로 target distribution에 대해선 옳게 잘 대답할 수 있음에도 underconfident하게 됐다. overfitting을 줄이기 위해 early-stopping을 했는데, 그 기준은 다음과 같다. fine-tuning의 목적은 pT와 pM을 같도록 하는 것에 있다. 따라서 pM을 계속 pT에 수렴하도록, 즉 pT의 loss를 계속 줄이는 데 반해 MSE loss가 평평해지거나 증가하는 경우 이를 signal to early stopping으로 간주한다.
- indirect logit generalizes well to multipy-divide: indirect logit하도록 finetuning된 GPT-3도 impressive calibration을 이루었다.
Stochastic Few-shot
stochastic k-shot setting에 대해서 어떻게 GPT-3의 calibration이 이루어지는지 실험했다.
k-shots GPT-3(without fine-tuned) with Expected Value decoding vs fine-tuned GPT-3 with greedy decoding
이때 Expected Value decoding이란 verbalized probability를 나타내기 위한 것으로(verbalized probability를 나타내기 위한 fine-tuning이 되지 않았으므로 따로 방법이 필요하다), top 5개의 token의 probability를 가중평균한 것이다.
그 결과, Figure 6과 같이 50-shots에서 fine-tuned GPT-3와 비슷한 calibration 성능을 보임을 확인할 수 있다. 이는 곧 GPT-3가 이미 calibrated confidence에 대한 latent representation을 가지고 있음과, 50개의 example만으로 task를 수행할 수 있음을 시사한다.

Explaining the performance of verbalized probability
지금껏 GPT-3가 uncertainty를 word로 표현하고 calibration을 새로운 테스크에 대해 잘 일반화할 수 있음을 확인했다. 그렇다면, 무엇이 GPT-3로 하여금 학습과 일반화를 가능하게 하는 것일까?
- Does GPT-3 just learn to output the logits?: Table 1에서 logit-based 방법보다 verbalized probability에서 더 일반화가 잘 된다는 사실을 확인했다. 또한, correlation in performance between verbalized probability and answer logit이 비례하지 않고 modest하다는 것을 확인했다. 따라서, GPT-3는 단순히 logit의 정보만을 사용하여 verbalized probability하지 않는다.
- Does GPT-3 just learn simple heuristics?: 단순히 GPT-3가 수가 더 크면 어렵기 때문에 낮은 확률을 부여하지는 않는다.
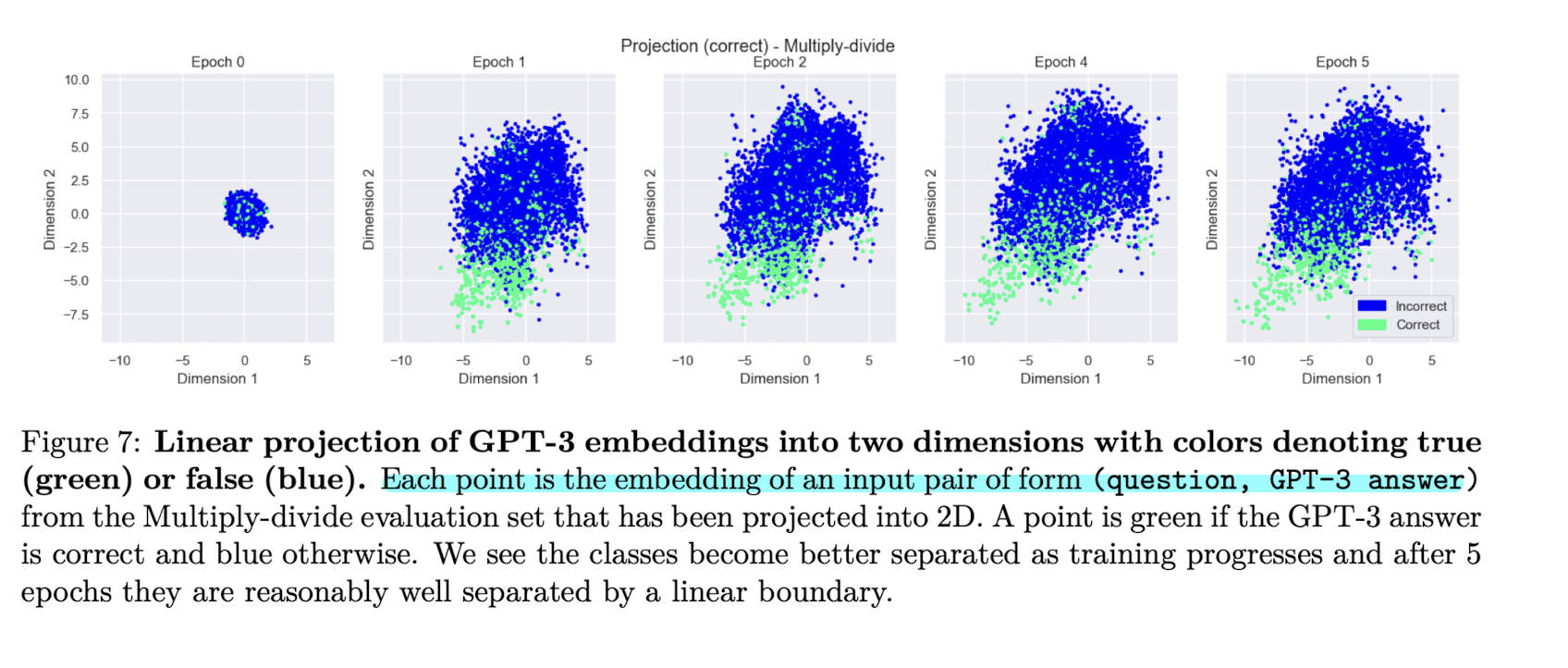
- Evidence that GPT-3 uses latent (pre-existing) features of questions: fine-tune하기 위해 GPT-3에 입력으로 들어가는 (question, answer)의 embedding을 GPT-3 finetuned for semantic similarity 모델을 통해 얻을 수 있다. 이 embedding을 latent representation이라고 하며, 이 embedding에 이미 calibration과 관련된 정보들이 담겨 있음을 Figure 7을 통해 확인할 수 있다. 즉, 이미 (question, answer)에 calibration에 필요한 정보가 encoding돼 있다.
Discussion
Directions for future work
본 논문의 결과는 GPT-3가 distribution shift에도 verbalized calibration을 할 수 있다는 것을 증명했다. 그러나 미래의 연구에서 단순히 이 결과가 간단한 수학 문제뿐 아니라 history, biology에도 적용될 수 있음과 chat, long-form QA와 같은 다양한 format에서도 적용될 수 있는지를 밝혀야 한다고 한다. 또한 fine-tuning 모델로 GPT-3 말고 다른 모델도 써보는 것을 권장하며, supervised leaninrg이 아니라 RL로 fine-tuning을 하는 방법도 제안한다.