Paper
https://arxiv.org/pdf/2410.09962
Introduction
benchmark의 종류
- discriminative evaluations: Y/N, multiple choices (e.g., object가 image에 존재하는가?)
- generative evaluations: MLLM의 response를 LLM evaluator로 hallucinate되었는지 아닌지 평가함
기존 benchmark & evaluation의 한계
- too simple to tell much on the cause of hallucination and to be applied to real-world scenario
- off-the-shelf object annotation을 benchmark에 그대로 사용하기 때문에 limited variability
- LLM evaluator을 사용하면 computationally intensive & unstable함
본 논문의 approach
- 2개의 MCQ (Multiple-Choice Question) 태스크를 이용
- hallucination discriminative: text가 hallucination을 포함하고 있는지 아닌지 (yes/no), 그 이유가 무엇인지를 MCQ로 고르게 함
- hallucination completion: prefix에 대한 continuation (yes/no와 그 이유)을 MCQ로 고르게 함
- long and complex context를 이용해 real-world and practical scenario에 대한 평가를 할 수 있음
- LongHallGen: GPT4v를 이용해 hallucination data을 생성하고 이를 MCQ format으로 구축하는 automated benchmark construction pipeline을 제시
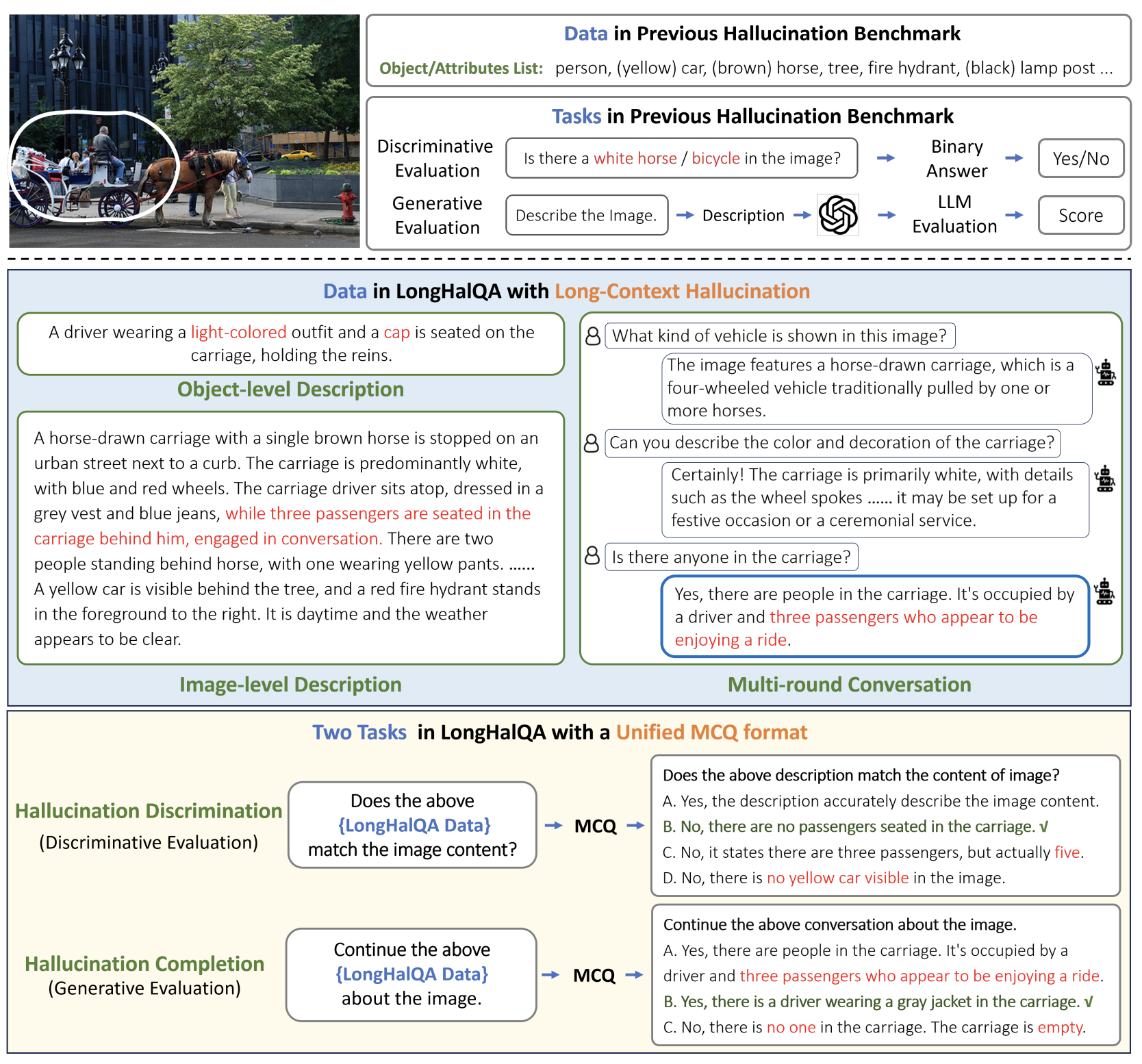
LongHalQA: Long-Context Hallucination Benchmark
Hallucination Discrimination
- yes로 시작하는 답변: text와 image가 match하다는 의견과 그 근거 제시
- no로 시작하는 답변: text와 image가 unmatch하다는 의견과 그 근거 제시
- 단순히 모델이 object existence를 아는지 모르는지가 아니라 모델이 text와 image의 상황에 대한 understanding을 평가
Hallucination Completion
- 원래 generative evaluation은 LLM evaluator를 이용해 느리고 비쌌음. 이를 MCQ 형태로 바꾼 것.
- image + related incomplete description / conversation을 준 뒤, 보기를 prefix에 대한 continuation으로 한 다음 모델에게 고르도록 함. 3개는 hallucinatory choices, 1개는 correct choice
Data Format
- object-level description: object, attribute, state, relation with other objects에 대한 묘사 (discriminative)
- image-level description: main contents, more details of an image (e.g., object, background, weather)을 묘사 (discriminative, completion)
- multi-round conversation: human user와 assistant가 대화한 내용을 묘사 (discriminative, completion)
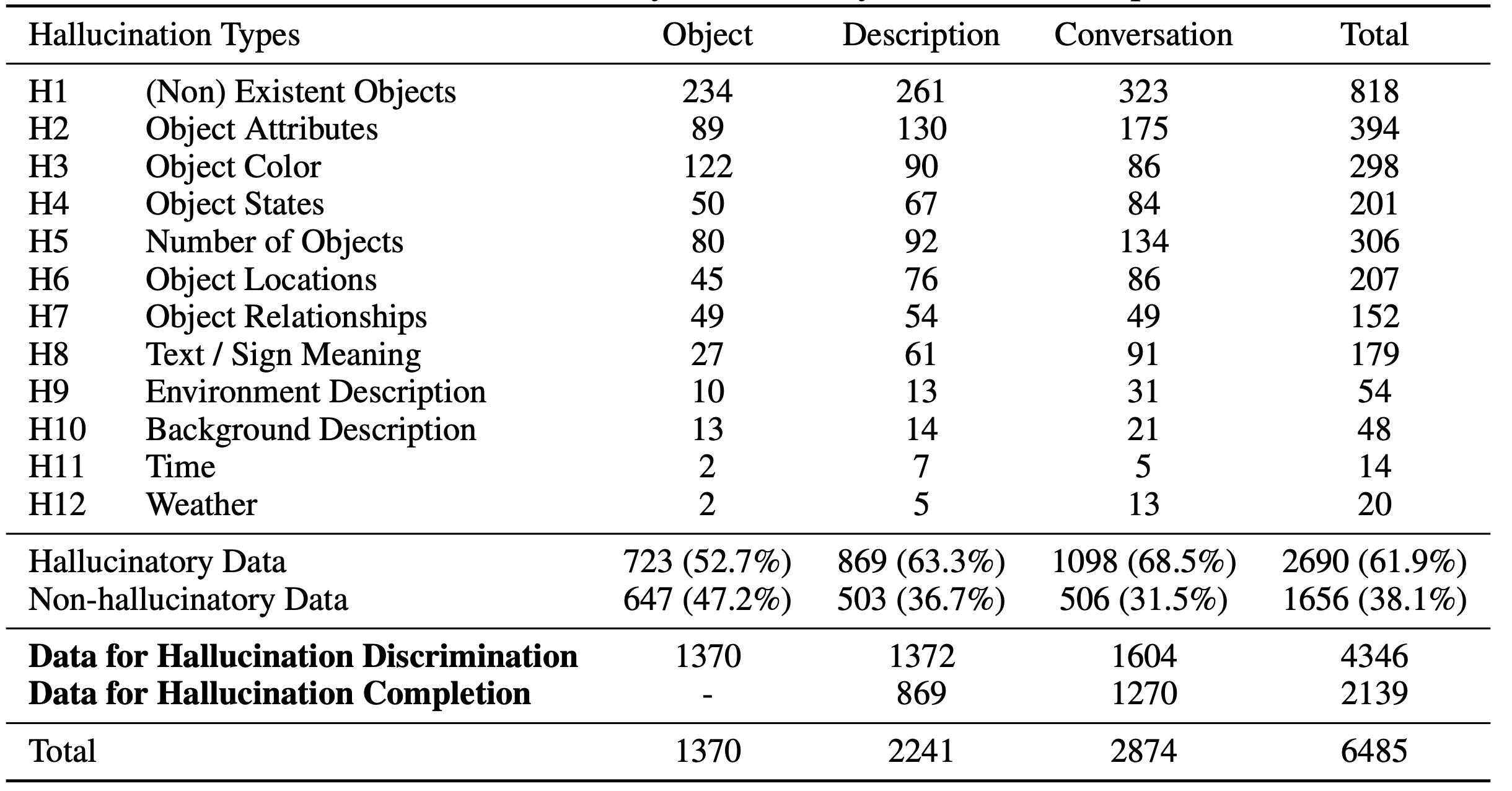
Types of Hallucination
- LongHalQA은 12가지 종류의 hallucination을 평가함
Complexity and Length of Text in LongHalQA
- average words object, image, conversation: 14, 130, 189 (<-> exisitng benchmarks: 80 words)
Evaluation methods and Metrics
- binary answers: acc, precision, yes ratio
- multiple-choice setting: (mc-) acc (randomly shuffled the order of the four options for fairness) =
LongHallGen: Automated Long-context Hallucination Data Generation
1. Image Collection and Filtering
- image를 수집해야 함 -> too simple / rare한 scene은 걸러야 함
- VisualGenome, Objects365 이미지셋에서 GroundingDINO 모델을 이용해 이미지 필터링
2. Positive Data Generation
- GPT4V한테 image를 입력으로 주어 long-context text 생성하라고 함
- 근데 생성된 text에서 hallucination이 발생할 수 있음
3. Hallucination Check
- GPT4V가 생성한 long context text를 GPT4V가 self-check함
- text로부터 object annotation 추출, GroundingDINO한테 image-annotation이 잘 맞는지 확인하라고 함 -> 결과를 다시 GPT4V한테 입력으로 주어 further checking
- 마지막으로, 사람이 long-context text 확인
4. Hallucination-Explanation Pair Generation
- text에 hallucination이 없는 경우: GPT4V한테 hallucination type 중에서 하나의 에러를 데이터에 생성하라고 함
- text에 hallucination이 있는 경우: GPT4V한테 데이터에 하나의 에러만 남기도록 수정하라고 함
- 너무 복잡해지는 것을 막기 위해 text 당 1개씩의 hallucination만 있도록 함
5. Question and Answer Generation
- generated HE pair를 이용해 GPT4V한테 MCQ 형태로 문제를 만들라고 함
- discriminative: 질문: Does the following {Hallucinated Data in HE pair} match the image content? / 정답: 4지선다
- completion: 질문: Complete the following {Hallucinated Data in HE pair} / 정답: 4지선다
Experiments
overall experiments
- Qwen2-VL-72B가 hallucination completion task에 대해 best performance를 보임
- MiniCPM-V2, Qwen2-VL-2B의 성능이 잘 나온 것으로 보아 reinforcement learning으로 hallucination 줄이는 훈련의 효과를 보임
- image의 resolution (해상도)가 좋아야 hallucination을 완화할 수 있음
experiments on hallucination discrimination
- binary setting: 대부분의 LLM이 long-context에 취약함
- multiple-choice setting: binary setting에 비해 성능이 좋음. 이는 binary setting과 달리 보기에 detailed explanation이 있기 때문에 모델이 상황을 더 잘 이해하여 보기를 선택할 수 있기 때문으로 추측됨.
experiments on hallucination completion
- high resolution image, multi-modal RLHF training이 중요함