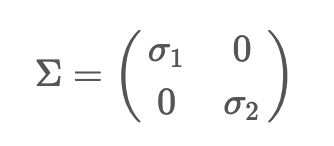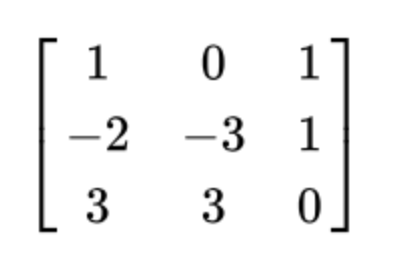SVD (Singular Value Decomposition)은 고유값 분해와 다르게 m != n인 (m, n)인 행렬에 대해서도 비대칭 행렬에 대해서도 모두 적용 가능한 행렬 분해법이다. SVD는 임의의 (m, n) 행렬 A = \(U \sum V^T\)로 분해한다.A: (m, n) rectangular matrixU: (m, m) orthogonal matrix\(\sum\): (m, n) diagonal matrix\(V^T\): (n, n) orthogonal matrixorthogonal matrix란 \(U U^T = I\)가 되는 행렬, 즉 \(U^T = U^{-1}\)인 행렬이다. diagonal matrix는 주대각성분을 제외한 나머지 성분이 모두 0인 행렬이다. SVD는 "직교하는 ..