1. What is Coreference Resolution?
coreference resolution(공동참조 해상도)이란 같은 개체를 참조하는 모든 mention을 찾는 것이다. coreference resolution은 full text understanding, machine translation, dialogue systems 등에서 활용될 수 있다.
크게 아래와 같은 두 개의 단계로 구성된다. mention을 탐지하고 각각의 mention이 무엇을 함께 참조하는지 clustering하는 것이다.

detect the mentions
mention에는 크게 세 가지 종류가 있다.
- pronouns(고유 명사): I, your, it, she, him... -> use a pos-tagging
- named entities: people, places, organizations... -> use NER
- noun phrases: a dog, the big fluffy cat stuck in the tree... -> use parser
그러나 mention detection이 쉬운 것은 아니다. 만약 가주어, 명확한 기준이 없는 것 등이 mention과 같은 format을 갖는다면 모델은 혼란스러워 할 것이다. 따라서 가짜 mention을 걸러내기 위해 일단 다음과 같은 작업을 할 수 있다.
- 모든 mention을 candidate mentions으로 둔 뒤 coreference system을 실행시킨다.
- 만약 그 무엇과도 짝지어지지 않은 mention이라면 singleton mention으로 간주한 뒤 처분한다.
pos-tagging, NER, parser 등 전통적인 방법 말고 mention detection을 위한 분류기를 학습시키는 방법을 생각해볼 수 있다. mention detection과 coreference resolution이 하나의 모델에서 end-to-end로 진행된다.
2. Linguistics related to Coreference
coreference
같은 개체를 참조하는 mention을 찾는 것으로, 예를 들어 'Barack Obama traveled to... Obama...'라는 텍스트가 있을 때 'Barack Obama'와 'Obama'는 coreference 관계로, Barack Obama라는 실제 인물을 직접적으로 공동으로 참조한다.
anaphora
coreference와 비슷하지만 엄연히 다른 언어학 개념이다.
예를 들어 'Barack Obama said he would sign the bill'이라는 문장이 있을 때 'Barack Obama'는 antecedent, 'he'는 antecedent를 참조하는 anaphora가 된다. 이때 anaphora는 Barack Obama를 직접적으로 참조하거나 나타내지 않고 Barack Obama를 참조하는 antecedent를 참조한다. anaphoric relation이란 anaphora가 antecedent를 참조하는 관계를 나타낸다.

그러나 모든 noun phrases가 coreferential한 것(어떤 것을 참조하는 것)은 아니다. 예를 들어 아래 예시에서처럼, 'Every dancer'는 정확히 누구를 나타내는지 모르는 불분명한 그룹이고 'No dancer'는 아무것도 지칭하지 않는다. 또한 'her knee'라는 명사구도 역시 해당 문장에서 특정한 것을 지칭하지 않는다.

bridging anaphora라는 것도 있다. 이는 아래 예시처럼 두 번째 문장은 첫 번째 문장에 의존하지만 'the tickets'이 첫 번째 문장의 어느 부분을 지칭하는 것이 없을 때 'the tickets'를 bridging anaphora라고 한다.

Cataphora
모든 antecedent가 anaphora에 선행하는 것은 아닌데, 이때 나중에 오는 antecendent를 미리 참조하는 것을 cataphora라고 한다.

3. Coreference Models
Rule-based
- Hobb's naive algorithm
- Knowledge-based Pronominal Coreference = Winograd Schema
- 첫 번째 예제는 형용사(full / empty)에 따라 it이 참조하는 대상이 달라진다.
- 두 번째 예제는 동사(feared / advocated)에 따라 they가 참조하는 대상이 달라진다.

=> 그러나, 단순히 rule-based가 아니라 semantically-based approach를 사용함으로써 문장의 의미를 이해하고 coreference 관계를 학습하는 것이 중요하다.
Mention Pair
가능한 모든 mention과 짝을 짓고 coreferent할 확률을 계산하는 binary classifier

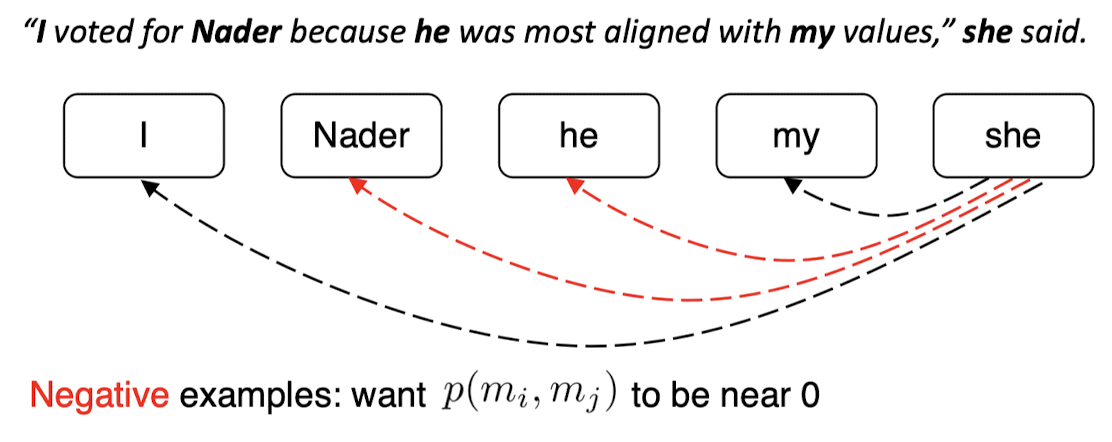
- mention pair training
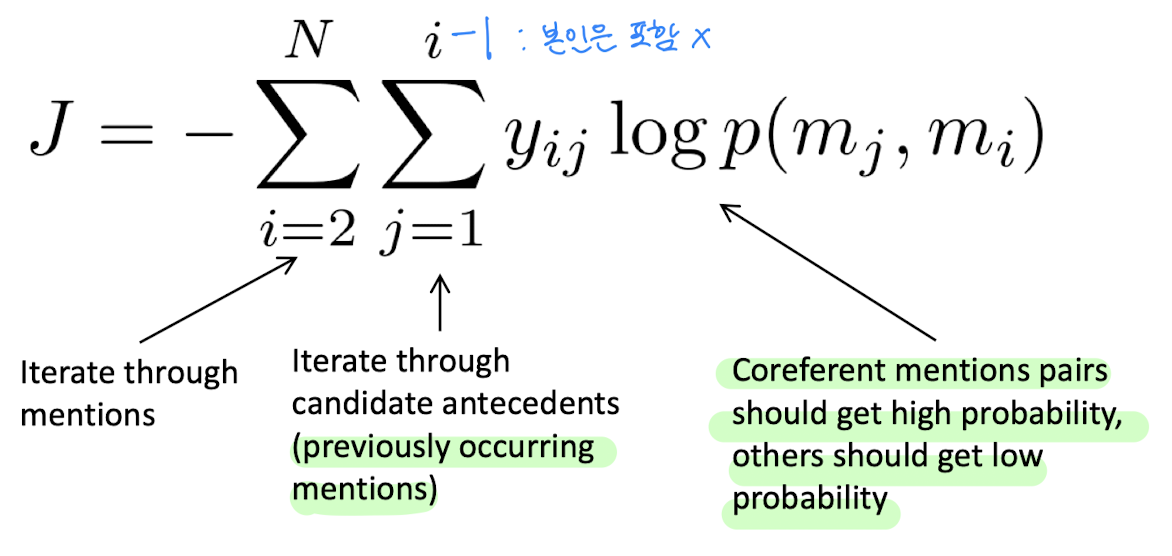
- mention pair testing
그러나 mention pair 모델은 멀리 있는 antecedent에 대해서는 쌍을 짓는 것이 거의 불가능하기 때문에, 모든 mention 쌍을 짓기보다는 각 mention별로 하나의 antecedent를 예측하도록 훈련하는 방법을 사용할 수 있다.
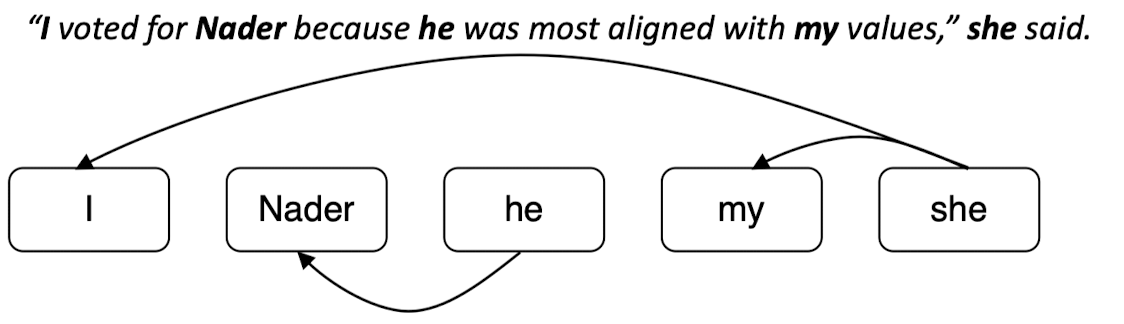
Mention Ranking
- 하나의 mention이 하나의 antecedent를 갖도록 하는 방법
- 'she'와 가장 높은 coreferent 확률을 가진 'I'와만 coreference link를 형성한다.
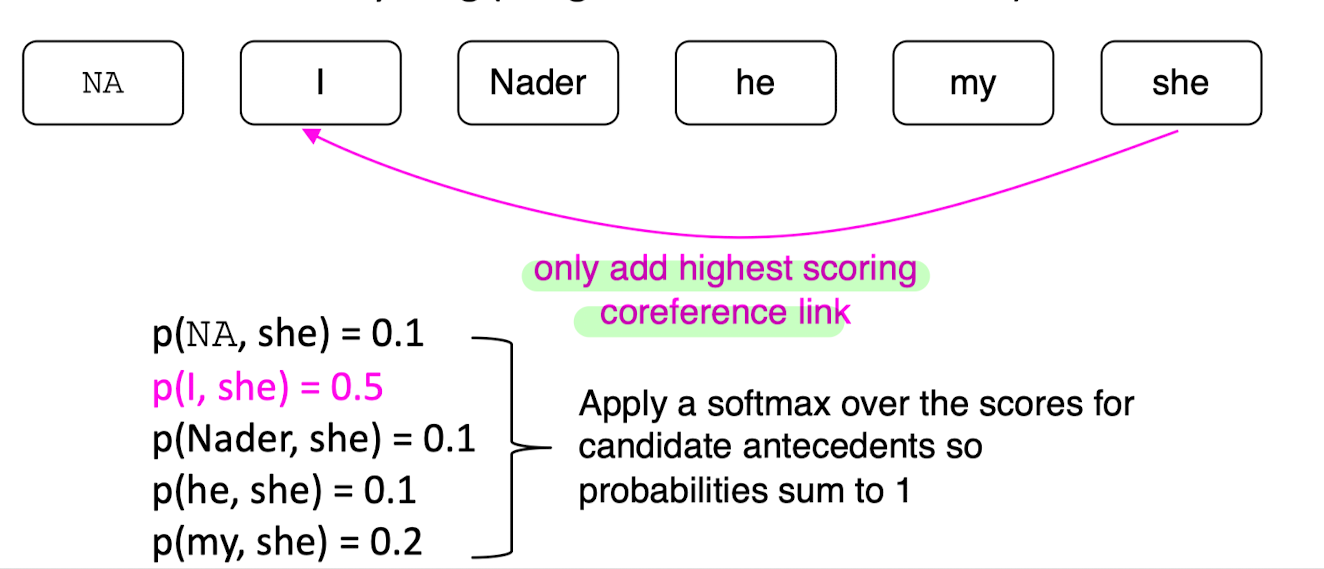
End-to-end neural coreference
- CNN-based coreference
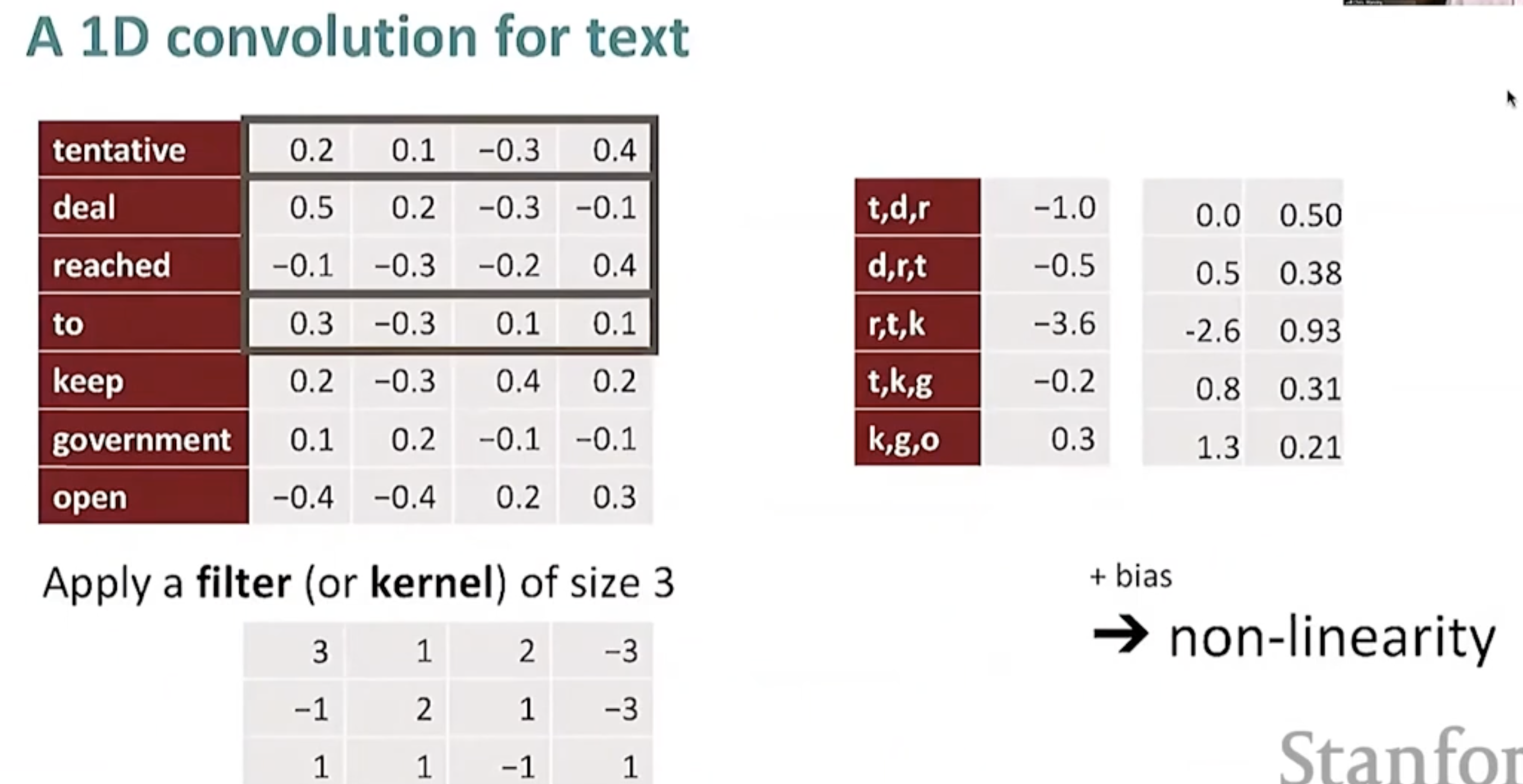
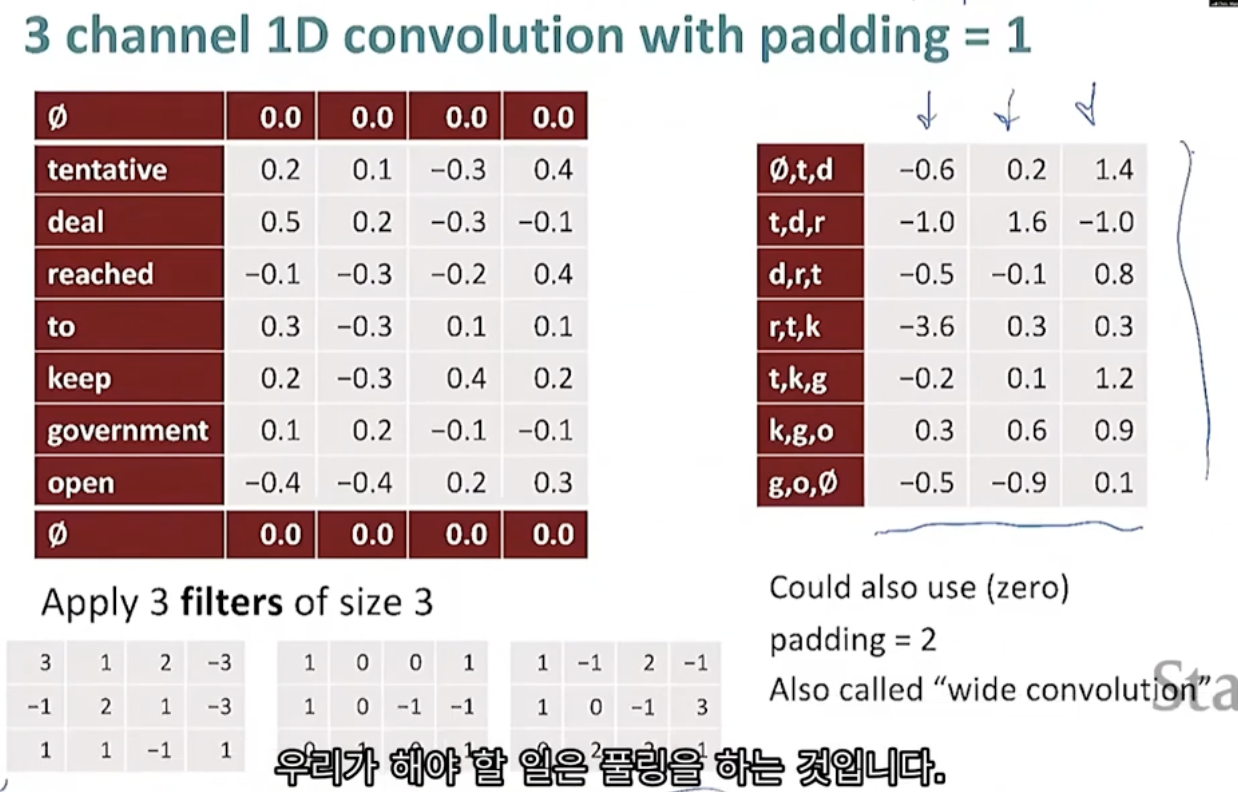

- neural coreference model
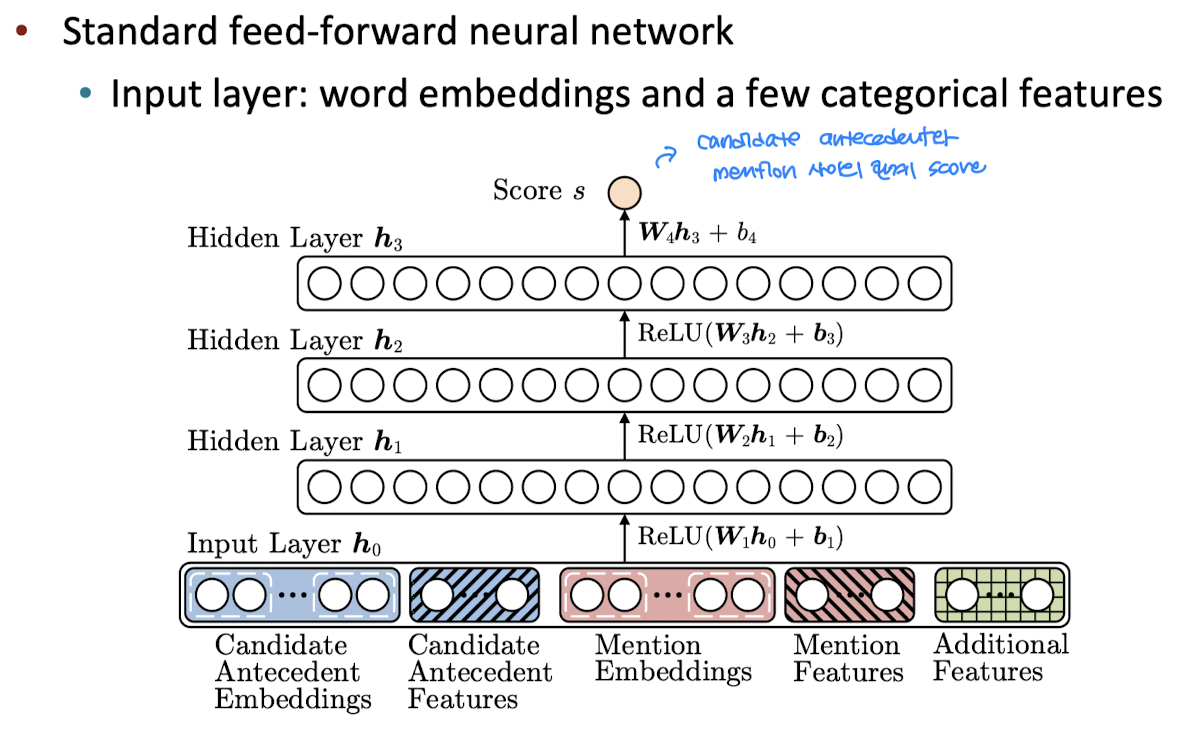
- input: candidate antecedent(1개) embeddings/features + current mention(1개) embeddings/features + additional features
- output: feed-forward NN을 통과시킨 candidate antecedent와 mention의 coreferent score
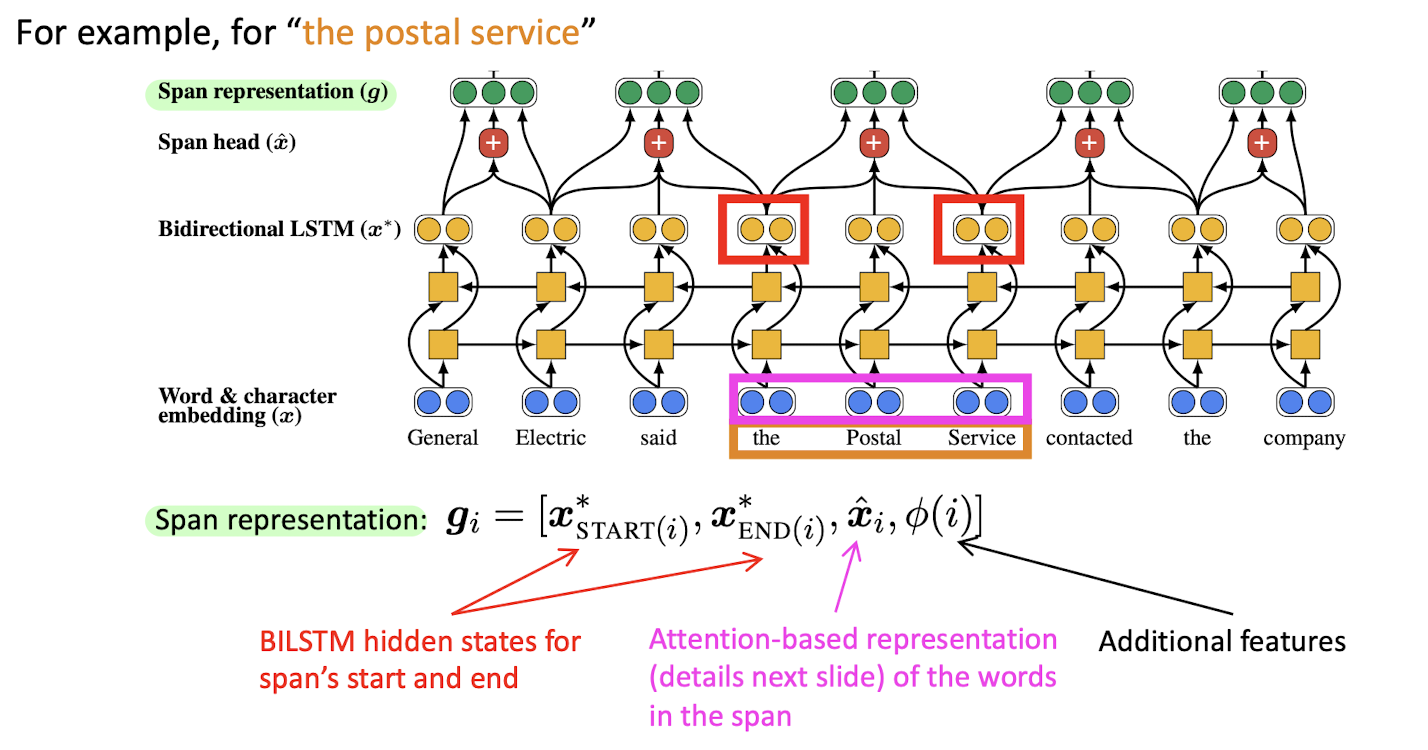
- word embedding과 character-level CNN(위의 예시에서는 단어 단위였지만 똑같은 과정을 character 단위로 해준다)을 사용하여 word를 벡터로 표현한다.
- bidirectional LSTM을 사용하여 context의 정보를 포착, 각 x는 이 정보를 담은 각 단어의 임베딩 벡터 x*로 변환된다.
- General, General Electric, General Electric said, ... , Electric, Electric said, Electric said the... -> span i에 대해 START(i)부터 END(i)까지의 모든 span을 벡터로 나타낸다.
- span head \(\hat{x}\)는 attention-based representation(self-attention)으로, span의 단어 사이의 관계에 대한 정보이다. 전체 임베딩 벡터 x*에 대한 attention scores를 계산 -> start(i)와 end(i) 사이의 attention scores만을 이용해 attention distribution을 구함 -> 그 결과를 이용해 가중평균 내어 attention output \(\hat{x}_{i}\)을 구함.

- span representation g: 아래 세 개의 벡터를 모두 concatenate한 것
- span의 start와 end의 BILSTM hidden states -> span의 왼쪽 / 오른쪽 문맥을 나타냄
- span 내 단어들 사이의 attention -> span 자체를 나타냄
- additional features -> span 밖에 있는 텍스트에 대한 정보를 나타냄
- 마지막으로 g를 사용해서 i가 mention인지, j가 mention인지, i와 j가 coreferent해 보이는지에 대한 score를 조합하여 span i와 span j가 coreferent한지에 대한 score를 산출하고 coreferent한지 결정한다.

- Transformer(BERT) - based coreference
- show good performance on long-term dependencies in text
- Idea1: SpanBERT -> span을 maksing하고 더 hard한 training 가능.
- Idea2: BERT-QA -> span 사이의 coreferent 관계를 question answering 형태로 묻고 답함.
- Idea3: span 단위가 아니라 word 단위로 coreference 관계를 학습할 수 있음.
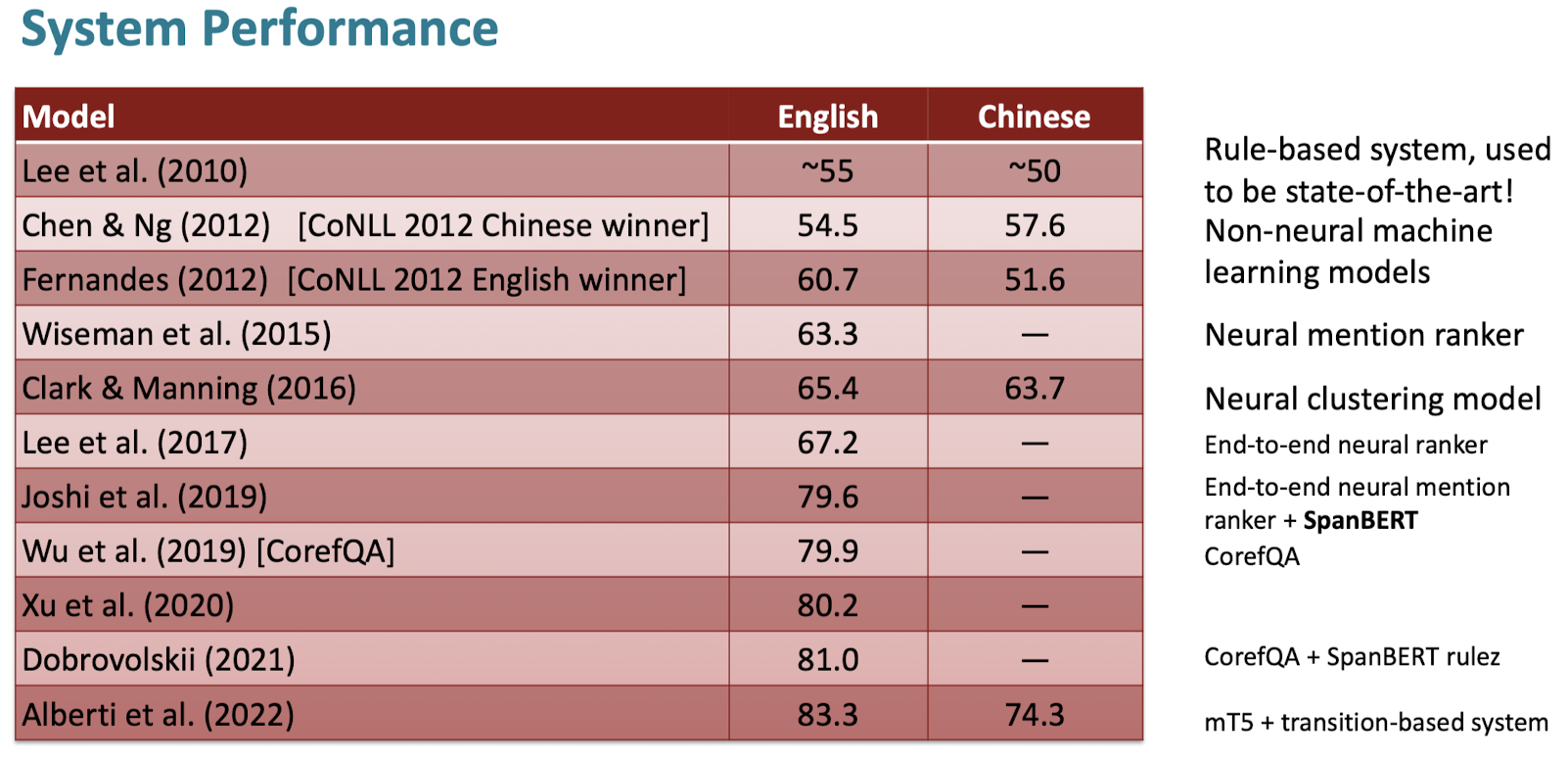
이 포스팅은 Stanford CS 강의 13단원에 기반하여 작성되었습니다.
'NLP > cs224n' 카테고리의 다른 글
| [cs224n] Question Answering (0) | 2024.07.08 |
|---|---|
| [cs224n] NLG(Natural Language Generation) (0) | 2024.07.06 |
| [cs224n] Prompting, RLHF (0) | 2024.07.05 |
| [cs224n] Pretraining (0) | 2024.07.03 |
| [cs224n] Self-Attention, Transformer (1) | 2024.07.03 |