📚 Paper
https://arxiv.org/pdf/2403.02509
Abstract
LLM은 잘못된 대답에 대해 과도한 자신감을 보이는 경향이 있다. 이 때문에 uncertainty quantification (UQ) 를 하는 것의 중요성이 부각되고 있다.
본 논문은 aleatoric uncetainty와 epistemic uncetainty를 모두 다루는 새로운 UQ 방법인 Sampling with Perturbation for UQ (SPUQ) 를 제시하고 있다. perturbation은 섭동이란 뜻으로, 간단히 '변화를 준다' 라는 뜻으로 이해하면 된다.
various LLM + various datasets을 이용해 다양한 perturbation / aggregation techniques를 조사했고, SPUQ를 이용해 Expected Calibration Error (ECE) 를 50% 줄이는 데 성공했다.
Introduction
머신 러닝에서 uncertainty는 aleatoric uncertainty와 epistemic uncertainty 이 두 가지가 있다.
- aleatoric uncertainty: natural language의 inherent variability (내재적 변동성) 로부터 발생하는 불확실성. 즉, same output에 대해서도 무수히 많은 valid outputs이 존재할 수 있기 때문에 발생한다. (aleatoric uncertainty에 대한 common approach는 (normalized) token likelihood가 있다. 그러나 ChatGPT / GPT-4와 같은 모델은 token likelihood에 대한 API를 제공하지 않는다. 또한, sampling-based method는 같은 input에 대해 여러 개의 outputs를 생성하여 그들이 얼마나 deviate한 지를 측정해 consistency를 평가한다. 그러나, 하나의 output을 생성하는 것을 sampling, 이를 반복해 여러 개의 outputs을 생성하는 것을 resampling이라고 하는데, 만약 잘못된 답이 여러 번 생성된다면 poorly calibrated될 수 있다.)
- epistemic uncertainty: insufficient data 또는 suboptimal modeling으로부터 발생하는 불확실성. 모델이 데이터를 잘 학습하지 못하거나 새로운 상황에 대한 generalization을 하지 못하는 한계 때문에 발생한다.
📌 SPUQ는 perturbation module을 이용해 epistemic uncertainty를 평가 (original temperature와 prompt에 여러 변화를 줌으로써 모델이 input에 얼마나 sensitive한 지를 평가한다 -> 같은 의미의 다양한 형태의 input에 대해 얼마나 consistent하게, 낮은 uncertainty로 잘 대답하는지를 보고 싶은 듯 (모델의 uncertainty) ) 하고 sampling multiple outputs from LLM을 통해 aleatoric uncertainty를 평가 (same input에 대해 다른 형태의 여러 output을 비교함으로써 얼마나 consistent하게, 낮은 uncertainty로 잘 대답하는지를 보고 싶은 듯 (output의 uncertainty) ) 한다. 또한 aggregation module을 이용해 total uncertainty를 계산한다.
SPUQ: Sampling with Perturbation for Uncertainty Quantification


Figure 1의 비교를 통해 알 수 있듯, SPUQ는 기존의 sampling-based UQ에서 perturbation module을 추가한 방법이다. sampling-based UQ는 같은 입력에 대해 여러 개의 outputs을 생성한 뒤, majority voting을 통해 최종 output을 결정하고 그들 사이의 deviation을 통해 UQ를 계산한다. Figure 1과 Algorithm 1에서 SPUQ의 동작 방식을 알 수 있다. original temperature T0와 original prompt x0를 Figure 2와 같은 다양한 방식으로 perturbation 한 뒤 i = 0, 1, 2...k개의 (Ti, xi) 쌍을 LLM에 feed하여 k+1개의 output yi를 생성한다. (여기에서 sampling된다고 하는 것) 이후 aggregation module을 사용해 confidence score c를 계산한다.
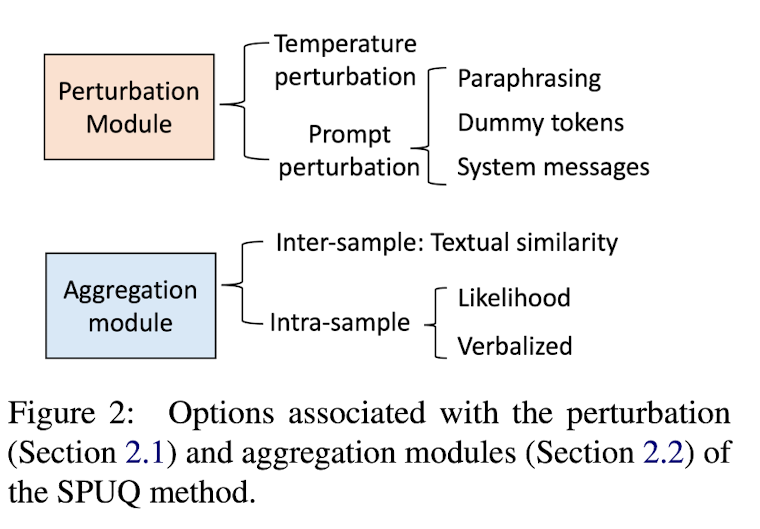
Perturbation Module
- temperature perturbation: T0로부터 일정하게 차이를 설정 / 각 output yi에 대해 random temperature 사용
- prompt perturbation: introduce lexical perturbation without altering the core meaning
- paraphrasing: ChatGPT에게 주어진 query로부터 k개의 paraphrase를 생성하라고 한다.
- dummy tokens: dummy tokens d (e.g., newline charaters, tab spaces, elipses, supplementary punctuation marks) 를 x0의 앞이나 뒤에 추가한다. -> xi = x0 + di or xi = di + x0
- system messages: system message는 LLM에게 '너는 이런 역할을 하는 모델이야' 라고 알려주는 메시지로, promtp x0는 그대로 두고 system message만 변경한다. 예를 들어 "You are a helpful assistant" 라는 system message를 "You are a question-answering assistant"와 같이 변경할 수 있다.
Aggregation Module
기존에는 exact match criterion, 즉 어떤 문장과 완전히 일치해야 1, 아니면 0을 주어 여러 개의 outputs yi를 비교했지만 이는 natural language에서는 적절하지 않은 방법이다. 본 논문에서는 confidence score을 계산하는 두 가지 방법을 제시한다.
- Inter-sample: outputs yi 사이의 textual similarity s(yj, yi)를 이용한다. 이때 j는 accuracy measurement의 기준이 되는 index로, j = 0, 즉 original prompt x0와 output y0를 사용한다. weight wi = s(x0, xi)인데, 이는 original prompt 0와 perturbed prompt xi 사이의 similarity이다. 이는 perturbed prompt가 너무 original prompt로부터 벗어나는 것을 방지하기 위한 것이다. s( , )로 BERTScore 또는 cosine similarity derived from SentenceBERT embeddings 또는 RougeL Score를 이용한다. (sampling-based UQ에서 majority voting은 Eq. (1)의 한 예시로, yj가 가장 많이 등장한 output일 때 다른 output yi와의 exact match를 계산한다. 또한 perturbation이 없으므로 all wi = 0이다.)

- Intra-sample: 각 샘플 (xi, yi)에 대한 confidence score c(xi, yi)를 계산하고 이를 평균내는 방법이다. c(xi, yi)를 계산하는 방법으로 첫째, token likelihood를 사용한다. (단, 이는 LLM API가 token likelihood를 제공할 때만 가능) 둘째, verbalized uncertainty strategy를 사용한다. (word / number로 UQ) LLM에게 UQ하도록 prompting함으로써 verbalized uncertainty를 얻을 수 있다.

Experimental Setup
- Large Language Models (LLMs) : GPT-3, ChatGPT, GPT-4, PaLM2, PaLM20Chat
- Datasets: summarization task dataset XSUM, classification-type dataset (StrategyQA, BoolQ), generation-type (CoQA, TruthfulQA)
- Baselines for uncertainty quantification
- likelihood: confidence score is defined as the length-normalized LM likelihood
- verbalized: words or numbers
- sampling without perturbation: subsitute the exact match criterion with textual similarity for s( , ) for fair comparison
- Evaluation
- Estimated Calibration Error (ECE)
- Bm: m번째 bin에 들어있는 샘플 수
- n: 전체 샘플 수
- acc(Bm): m번째 bin에 들어있는 샘플 중 y^ = y인 것의 개수의 평균 (옳은 것의 개수)
- conf(Bm): m번째 bin에 들어있는 샘플의 (predicted) confidence의 평균
- Pearson's correlation between confidence score c and accuracy
- compute accuracy via exact match criterion for classification-type datasets / F1 criterion for generation-type datasets
- hyperparameters for perturbations and aggregation will be fine-tuned with development set
- Estimated Calibration Error (ECE)




Results and Discussion
Enhanced Uncertainty Calibration
- likelihood: normalized token likelihood를 사용하기 때문에 API를 제공하는 GPT-3만 평가한다.
- Verbalized: LLM에게 추가적인 prompt로 verbalized uncertainty를 generate
- sampling-based UQ: 하나의 x0, T0에 대해 여러 개의 y를 generate (sampling) -> majority voting (가장 많이 등장한 ouput) + Eq. (1) with textual similarity를 이용해 confidence 계산
- SPUQ (only perturb T): temperature만을 perturb해서 LLM에게 feed -> i = 0...k 개의 output y를 생성 -> aggregation module을 이용해 confidence score c 계산
- SPUQ (perturb T & x): prompt와 temperature 모두 perturb해서 LLM에게 feed -> i = 0...k개의 output y를 생성 -> aggregation module을 이용해 confidence score c 계산
이렇게 각각의 방법으로 confidence를 계산한 후, ground-truth uncertainty와 ECE를 계산하여 얼마나 well-calibrated 했는지를 평가한다. Figure 3에서, SPUQ가 baseline에 비해 ECE가 낮아 well-calibrated 된 것을 확인할 수 있다.
(output y를 decoding하는 방식은 명시되지 않았고, 각 LLM의 원래 decoding 방식에 의존하는 듯함.)

Table 1은 case study로, perturbation의 중요성을 보인다. LLM은 잘못된 prediction에 대해 overconfident할 때가 있다. 예를 들어 Table 1의 Original 처럼 No는 incorrect prediction이지만 그 likelihood는 92%로 출력했다. 반면, paraphrasing (prompt perturbation)은 네 가지의 epistemic uncetainty, 즉 prediction instability를 평가한다. Table 1의 예제에서 모델은 4개의 perturbed prompt에 대해서 정답 yes를 두 번만 맞혔으니 confidence score (accuracy) 는 0.5로 예측해야 할 것이고, 이는 모델의 overconfident를 방지한다. 그 증거로, Figure 6에서 SPUQ의 distribution of confidence score가 sampling-based UQ에서보다 더 flatter한 것을 볼 수 있다.


Dependence on Hyperparameters
- numebr of perturbed samples: 샘플 수가 많을수록 UQ가 reliable해진다. k = 5일 때부터 improvement가 시작한다.
- temperature perturbation: temperature가 높을수록 output y의 probability distribution이 더 uniform (evenly) 해진다. 이는 LLM overconfident를 막고, temperature가 높아질수록 ECE 가 줄어들어 superior calibration을 할 수 있다.
- prompt perturbation: paraphrasing과 다르게 dummy token와 system message는 prompt에 직접적인 변화를 주지 않는 방법이다. paraphrasing할 때 superior calibration 을 보였다. Figure 7 참고.
- aggregation module: inter-sample과 intra-sample aggregation module 모두 좋은 성능을 보인다. similarity s( , )으로는 RougeL을 사용해 confidence score를 계산하는 것이 가장 뛰어난 성능 (well-calibration) 을 보였다.
- robustness to the development set: 5개의 다른 development set을 사용해서 SPUQ의 hyperparameter를 fine-tuning했다. Table 2 참고.

