📚 Paper
https://arxiv.org/pdf/2303.08896
https://rosanneliu.com/dlctfs/dlct_230811.pdf
Abstract
LLM이 hallucinated facts와 non-factual statements를 생성하는 현상에 대한 해결책으로 현존하는 방법은 access to the output probability distribution 또는 access to external database가 있다.
본 논문은 SelfCheckGPT를 제시한다. SelfCheckGPT는 black-box model의 text generation을 zero-source fashion (without token probability and external database)으로 hallucinate되었는지를 평가한다.
언어 모델은 공개 정도에 따라 white-box, grey-box, black-box로 나뉜다. white-box는 완전히 open-source로, 모델의 internal states와 output 모두 접근 가능하다. grey-box는 모델의 internal states는 알 수 없지만 output의 일부, 예를 들어 token probability distribution과 top-5 token 대한 정보를 얻을 수 있다. black-box는 모델의 text output밖에 알지 못하도록 완전히 모델의 파라미터와 internal states에 대한 접근이 제한된다.

SelfCheckGPT는 LLM이 주어진 query에 대해 certain하다면 stochastically sampled responses가 similar and consistent하고 반대로 hallucinated fact에 대해서는 stochastically sampled reponses가 diverge and contradict하다는 개념을 이용한다.
본 연구는 SelfCheckGPT가 grey-box method에 비해 뛰어난 1) detect factual and non-factual sentences와 2) rank passages in terms of factuality를 할 수 있음을 GPT-3와 Wikibio dataset을 활용하여 보인다.
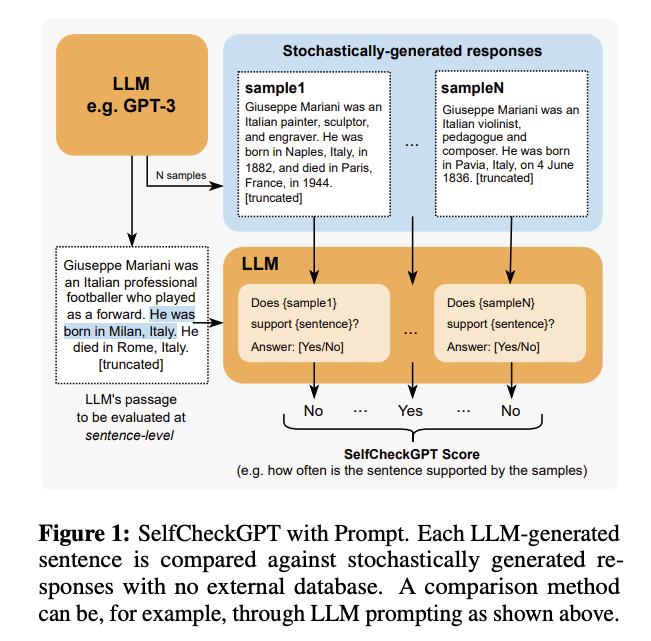
Introduction
exisitng uncertainty estimation metric은 token prob.나 entropy를 이용하는데, 이는 API가 제공되지 않는 모델에 대해서는 사용할 수 없다는 한계가 있다. fact-verification을 할 수 있는 possible alternate approach으로는 external database로부터 generation을 평가할 수 있는 source를 찾는 것이다. 그러나, 이 역시 database 내에 어떤 정보가 있느냐에 따라 평가되기 때문에 절대적인 평가 지표가 되기는 부족하다.
SelfCheckGPT는 sampling-based approach로 hallucination detection을 한다. 모델의 main response를 같은 query에 대해 생성된 stochastically sampled responses와 비교하여 main response가 consistent / trustworthy한 지를 평가한다. 논문에서는 use only generations sampled from model을 강조하는데, 그 방법으로 BERTScore, question-answering, n-gram, NLI, and LLM prompting이 있다.
Background and Related Work
Hallucination of LLMs
- train a multi-layer perceptron classifier where an LLM's hidden representations are used as inputs to predict the truthfulness of a sentence -> confined to white-box LLM which can utilize the internal states
- self-evaluation where an LLM is prompted to evaluate its previous prediction whether it is true or false
GPT-3는 token probability와 top-5 token을 공개하는 grey-box LLM이다.
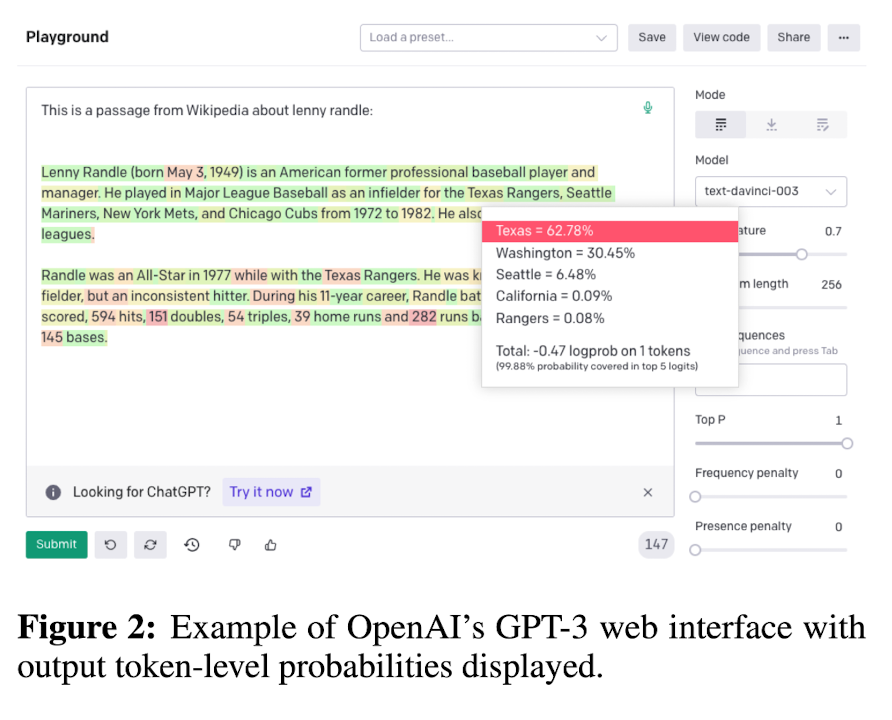
Grey-Box Factualilty Assessment (where token probabilities are available)
full access to output distribution일 때 zero-resource setting에서 LLM response의 factuality를 평가하는 방법을 소개한다. (즉, in grey-box fashion)
-> facutal when valid information is grounded behind the claim
먼저, LLM pre-training 과정을 알아야 한다. pre-training 때 모델은 massive textual data corpora에 대해 next word prediction을 목적으로 훈련된다. 예를 들어, "Lionel Messis is a _"이라는 상황에서 _에 들어갈 말을, 모델은 pre-training 때 메시에 대한 언급을 여러 차례 확인했을 것이기 때문에 "footballer"라는 토큰에 대한 확률을 다른 토큰에 비해 매우 높게 줄 것이다. 그러나, "John Smith is a _"라는 문장에 대해서는 pre-training 때 학습 또는 확인된 바 없기 때문에 "footballer", "carpenter", "cook".. 등등에 대해 flat output distribution을 가질 것이다. 따라서 이 경우에 stochastically response sampling을 하면 diverge & contradict한 결과를 보일 것으로, main response가 non-factual하다고 판단할 수 있다. 즉, factual sentence는 tokens with high likelihood and lower entropy를 포함하고 hallucinated sentence는 tokens came from flat distribution with high entropy를 포함한다.
Token-level Probability
notation
- R: LLM's main response as a passage form which consists of several sentences
- i-th sentence in R
- j-th token in i-th sentence
- J: the number of tokens in i-th sentence
- p_ij: probability of word generated by the LLM at the j-th token position in i-th sentence

Avg(-logp)는 i-th sentence를 이루고 있는 토큰들의 negative log likelihood의 평균으로, 이 값이 클수록 i-th sentence는 uncertain함을 의미한다. Max(-logp)는 i-th sentence를 이루고 있는 토큰들의 negative log likelihood 중 가장 큰 값으로, 가장 uncertain (least likely generated) 한 토큰의 negative log likelihood이다.
Entropy
W는 output distribution에 있는 모든 possible vocabulary이고, tilde w는 i-th sentence의 j-th token이다. 즉, W에 있는 모든 word에 대해 그 word가 i-th sentence의 j-th token 자리에 올 token-wise entropy의 합이 H_ij이다. Avg(H)는 i-th sentence의 token-wise entropy average이고 클수록 i-th sentence는 uncertain하다. Max(H)는 i-th sentence의 토큰 중 가장 flat (uncertain) distribution을 가지는 토큰의 entropy이다.


Black-Box Factualilty Assessment
black-box approach는 text-based output만이 available할 때도 applicable하다.
proxy LLM은 LLaMA와 같이 full access 모델을 사용해 black-box LLM의 output token-level probabilities를 근사할 수 있다.
SelfCheckGPT
Notation
- R: main response of LLM to given user query as a passage which consists of serveral sentences
- SelfCheckGPT draws N stochastic LLM response samples using the same query with R
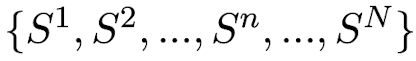
-> measure the consistency between main response R and stochastically sampled responses: SelfCheckGPT predict the hallucination score of the i-th sentence, S(i) which is in range [0.0, 1.0]. S(i)가 0일수록 i-th sentence는 factual하고 1일수록 i-th sentence는 hallucinate된 것이다.
SelfCheckGPT with BERTScore
B(,)는 RoBERTa-Large로 계산한 BERTScore이다. ri (R에 있는 i-th sentence)와 s_k^n (n번째 sample response의 k번째 sentence) 사이의 k에 대한 BERTScore 중 최대값을, N개의 sample response에 대해 반복한다. 평균 낸 값이 클수록 ri가 consistent (certain)하다는 뜻으로 hallucination score가 작아진다.

SelfCheckGPT with Question Answering
MQAG (Multiple-choice Question Answering Generation) framework를 사용하여 consistency를 계산할 수 있다. MQAG는 main response에 대한 multiple-choice questions를 생성한 뒤, independent answering system으로 하여금 그 질문에 대한 답을 맞추도록 한다. Eq. (2)는 question generation G stage이다. G stage는 크게 main response ri의 정보를 활용하여 {question, answer} pair를 generate하는 G1과 q, a, R이 주어졌을 때 오답 o\a를 생성하는 G2로 이루어져 있다. 최종적으로 정답 선택지는 o = {a, o\a} = [o1, o2, o3, o4]이 된다. 또한, bad (unanswerable) question을 filter out하기 위해 answerability score alpha를 설정한다. Eq. (15)에서 context는 R 또는 S^n으로, 이를 고려했을 때 alpha = 0.0이면 q는 unanswerable하고 1.0이면 q는 answerable한 것이다. 본 논문에서는 alpha를 threshold로 잡았을 때 question의 alpha가 alpha 이하이면 unanswerable question으로 분류하고자 했다.
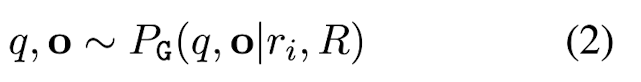
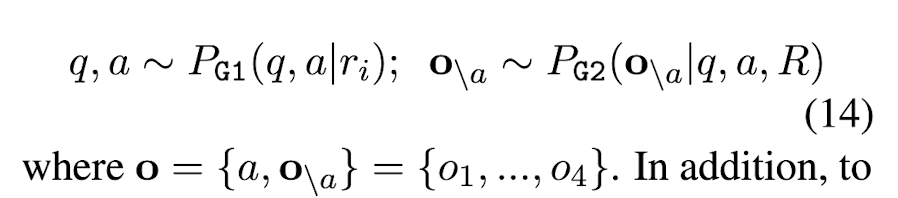
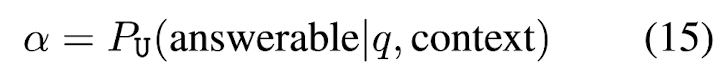
이후 answering stage A을 진행하여 main response R (passage)가 주어졌을 때의 q의 정답 o aR과 n-th sampled response S^n (sampled passage)가 주어졌을 때의 q의 정답 o aS^n을 구한다. 이를 N개의 sampled response에 대해 반복한 뒤 Nm을 aR = aS^n의 개수, Nn을 aR != aS^n의 개수라고 한다.
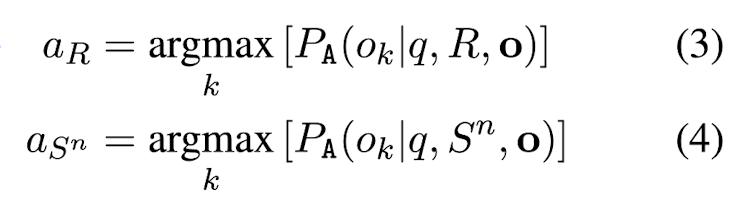
Nm과 Nn을 이용하여 i-th sentence에 대한 hallucination score을 직관적으로 구하면 다음과 같다.

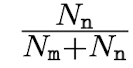
그러나 본 논문에서는 answerability를 고려한 새로운 식을 정의한다.
P(F)를 i-th sentence가 non-factual할 확률, P(T)를 i-th sentence가 factual일 확률이라고 하자. Lm을 a set of aS^n which is a matched answer (aR == aS^n), Ln을 a set of aS^n which is unmatched answers (aR != aS^n)이라고 할 때, Lm과 Ln이 주어졌을 때 i-th sentence가 non-factual일 확률을 bayes 정리를 이용하면 다음과 같이 나타낼 수 있다. P(F) == P(T)라고 가정하면 약분된다.

i-th sentence가 non-factual일 때 Lm, Ln이 observe될 확률은, P(a' != aR|F) = beta1라고 하면 Eq. (17)과 같이 나타낼 수 있다. Lm의 원소는 Nm개, Ln의 원소는 Nn개로, Nm + Nn = N이다.

i-th sentence가 factual일 때 Lm, Ln이 observe될 확률은, P(a = ar|T) = beta2라고 하면 Eq. (18)과 같이 나타낼 수 있다.
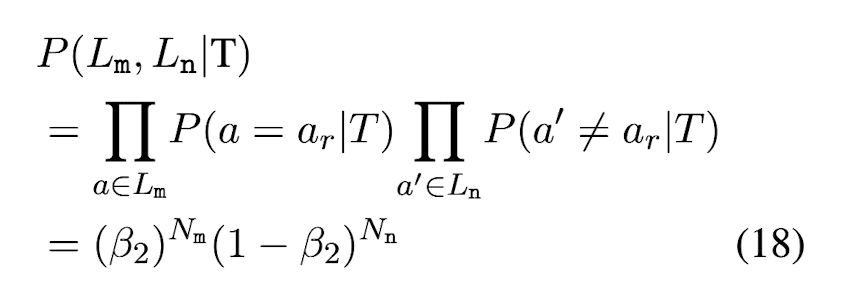
Eq. (17)과 Eq. (18)을 Eq. (16)에 대입하면 Eq. (19)의 결과를 얻을 수 있다. 논문에서는 beta1 = 0.8, beta2 = 0.8로 설정했다.

마지막으로, answerability를 반영해줘야 하는데 본 논문에서는 경험적으로 alpha 이하의 점수를 가지는 question을 filter out하기보다 Eq. (20)과 같이 alpha를 이용해 Nm과 Nn을 각각 Nm'과 Nn'으로 soft counting해주는 것이 성능 향상에 도움이 된다는 것을 밝혔다. an은 정의에 따라 Lm 또는 Ln에 있는 ground-truth 정답이고, alphan은 그 question에 대한 answerability score이다. 즉, Nm'은 aR == aS^n인 경우의 S^n에 대한 answerability의 합이고 Nn'은 aR != aS^n인 경우의 S^n에 대한 answerability의 합이다.

Eq. (5)의 과정을 i-th sentence에 대해 많은 question을 생성함으로써 반복한 뒤 기댓값을 구하면 최종적으로 i-th sentence에 대한 hallucination score를 계산할 수 있다. Eq. (6)의 값이 높을수록 i-th sentence는 non-factual할 확률이 높다.


SelfCheckGPT with n-gram
LLM's token probability에 근사할 수 있는 새로운 language model인 n-gram language model을 만든다. main response R과 samples {S^1, S^2...S^N}을 training data로 사용해서 n-gram model을 훈련시킨다. 예를 들어, 4-gram이라고 했을 때 예측하고자 하는 단어 w의 확률을 w 전 n-1 = 3개의 시퀀스가 corpus에서 나올 확률을 분모에 두고 3개의 시퀀스 + w가 corpus에서 나올 확률을 분자로 둬서 구할 수 있다. tilde p_ij는 n-gram model로부터 얻은 probability of j-th token in i-th sentence이다.
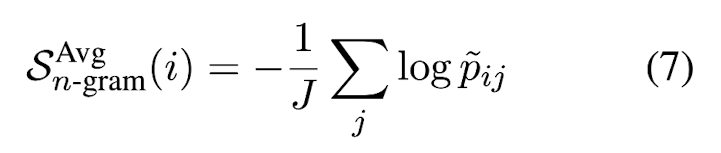
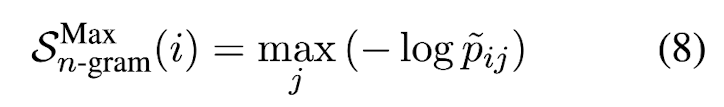
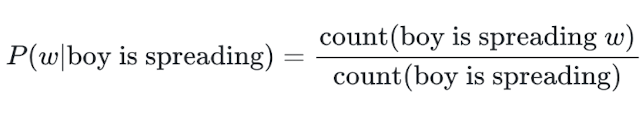
SelfCheckGPT with NLI
MNLI 데이터셋으로 NLI task에 대해 fine-tuninge된 DeBERTa-v3-large 모델을 사용한다. NLI classifier의 입력은 일반적으로 premise + hypothesis로, 주어진 premise에 대해 hypothesis가 entailment / neutral / contradiction인지를 분류한다. 본 논문에서는 ri + S^n을 NLI의 입력으로 사용하고 있다. output logit은 Eq. (9)처럼 normalization을 통해 neutral 없이 entailment와 contradiction 두 가지만 고려할 수 있다. ze는 entailment logit, zc는 contradiction logit이다. i-th sentence에 대한 hallucination score는 ri + S^n이 입력으로 주어졌을 때의 contradiction probability를 모든 N에 대해 반복한 것의 평균으로 정의한다.
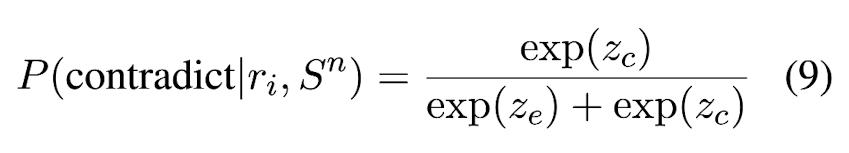

SelfCheckGPT with Prompt
마지막으로, 그냥 직접 LLM에게 i-th sentence (context)가 S^n (sentence)와 consistent한 지를 prompting한다. output from prompting은 {Yes: 0.0, No: 1.0, N/A: 0.5}로 mpping되어 i-th sentence에 대한 hallucination score가 계산된다.


Data and Annotation
전체적인 흐름은 다음과 같다.
1) generating synthetic Wikipedia articles using GPT-3 on the individuals/concepts from the WikiBio dataset
2) manully annotating the factuality of the passage at a sentence level
3) evaluating the system's ability to detect hallucinations
Wikibio dataset is a dataset where each input contains the first paragraph along with tabular information of Wikipedia articles of a specific concept. (어떤 개념에 대한 위키피디아 article의 첫 번째 paragraph와 tabular info box) Wikibio test set 중 paragraph 길이가 가장 긴 상위 20%의 238개의 article을 고른 뒤, 그 article의 concept에 대해 GPT-3 (text-davinch-003)로 하여금 새로운 article을 generate하도록 한다. 그 결과, wikibio GPT-3 dataset은 총 238개의 passage를 generate했으며 전체 sentence 개수는 1908개이고 하나의 passage 당 대략 184.7개의 토큰으로 구성되어 있다.


이렇게 GPT-3 generated passage에 대해, passage 내 sentence 하나하나에 manually annote했다. annotated class는 다음과 같다. major inaccurate(1)는 아예 context와 irrelevant할 때, minor inaccurate(0.5)는 context와 relevant하지만 non-factual일 때, accurate(0)는 context와 relevant하고 factual인 sentence일 때로 분류한다.

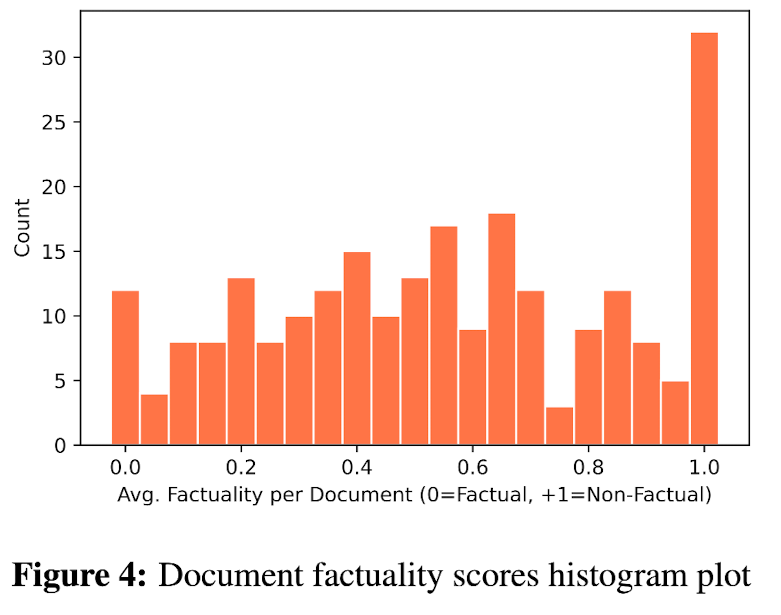
1908개의 sentence를 annotate한 결과, 761개는 major-inaccurate로, 631개는 minor-inaccurate로, 516개는 accurate로 분류됐다. 그 중 201개는 두 명의 annotator이 함께 annotation을 했는데, 의견이 일치하면 그걸로 하고 의견이 엇갈릴 때는 worse-case로 labeling했다. (major inaccurate < minor inaccurate < accurate) Cohen's k로 inter-annotator agreement의 정도를 측정했을 때 moderte and sbstantial agreement의 결과가 나와 sentence-level에서 non-factual과 factual의 annotation이 잘 됐음을 검증했다.
더 나아가, each passage 내의 sentence-level label (1, 0.5, 0)을 평균냄으로써 passage-level score도 계산할 수 있다. Figure 4에서 한 passage를 이루고 있는 모든 sentence가 major inaccurate인 경우에는 passage-level score도 1.0인데, 이 경우를 total hallucination이라고 한다.
Experiments
- to obtain main response (passage) from GPT-3 -> temperature = 0.0 and use beam search
- to obtain stochastically generated samples from GPT-3 -> temperature = 1.0 and N = 20
- for proxy LLM approach -> use LLaMA
- for SelfCheckGPT prompt -> use GPT-3 and ChatGPT
Sentence-level Hallucination Detection
- non-factual class: major-inaccurate / minor-inaccurate sentences
- factual class: accurate sentences
- +) non-factual*: major-inaccurate in passages that are not total hallucination passages (이 케이스를 추가로 만듦으로써 한 passage 안에 factual / non-factual sentence가 마구 섞여 있어도 non-factual인 것을 잘 detect하는지를 확인하고자 한 것으로 보임)
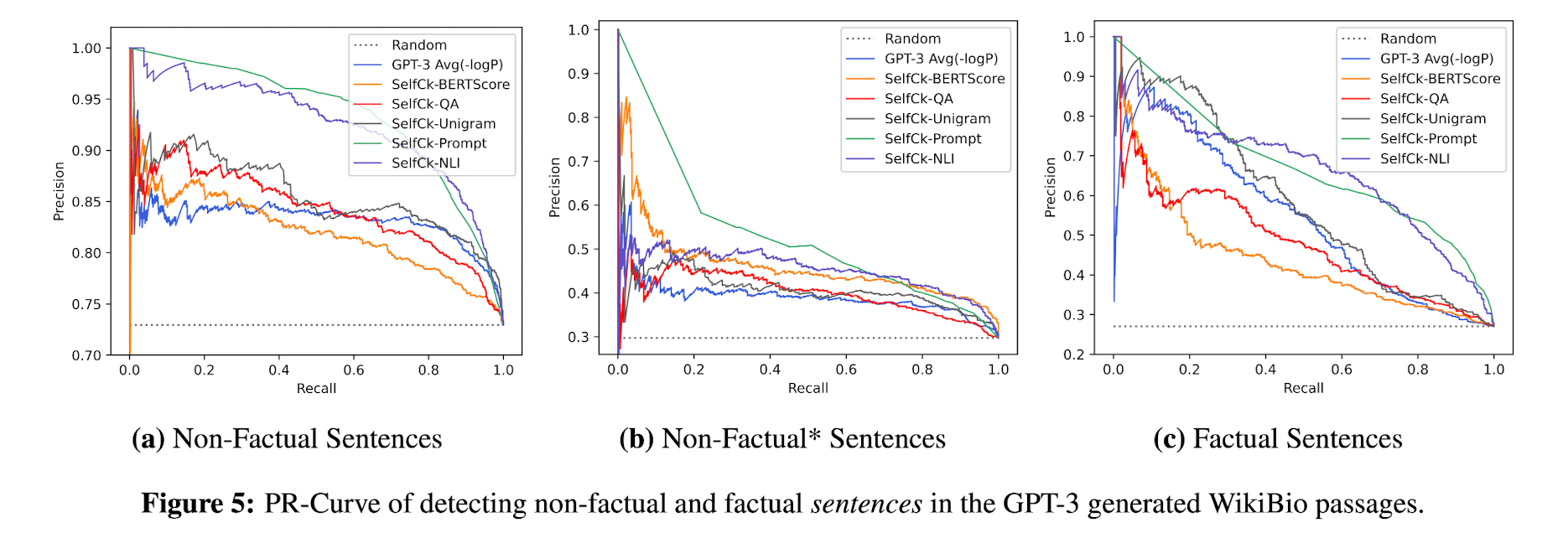
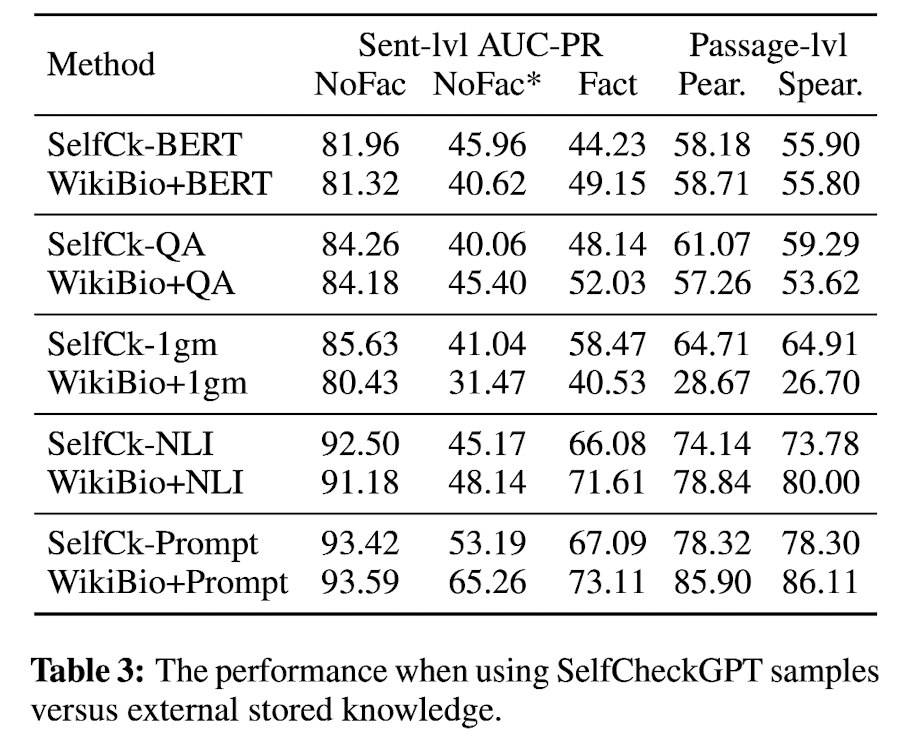
- LLM's probabilities p correlate well with factuality: GPT-3와 같은 grey-box로부터 output token probability를 뽑을 수 있는데, 이는 factuality를 평가하는 데 있어 좋은 baseline이 된다. factual sentence를 random 27.04에 비해 token probability를 이용한 Avg(-logp)는 53.97로 상당히 잘 분류했다. (non-factual sentence에 대해서도 마찬가지로 잘 분류함)이는 token probability가 uncertainty를 measure하는 데 유용하다는 것을 의미한다.
- Proxy LLM perform noticeably worse than LLM (GPT-3): GPT-3에 비해 좋은 성능을 보이지 못했다. 이는 GPT-3와 LLaMA가 다른 generating pattern을 학습하기 때문인 것으로 보인다. proxy LLM은 human judgement와의 alignment도 낮은 correlation을 보였다.
- SelfCheckGPT outperforms grey-box approaches: SelfCheckGPT는 grey-box approach를 능가한다. 주목할 만한 것은, 가장 비용이 적게 드는 방법인 SelfCheckGPT w/ unigram (max)가 상당히 좋은 성능을 보인다는 것이다. 상기하자면, 이 방법은 i-th sentence에서 n-gram model이 제공하는 j-th probability 중 가장 작은 probability를 hallucination score로 사용하는 것이다. (이는 곧 적게 N개의 sample response + R에서 적게 등장하는 단어를 그냥 non-factual하게 본 것이다.)
- SelfCheckGPT with n-gram: Avg보다 Max를 사용하는 것이 성능이 더 좋았고, n이 작을수록 더 성능이 좋았다.
- SelfCheckGPT with NLI: SelfCheckGPT with prompt 다음으로 가장 성능이 좋았다. prompt는 computationally expensive하므로 performance와 cost의 trade-off 측면에서 가장 좋은 방법이다.

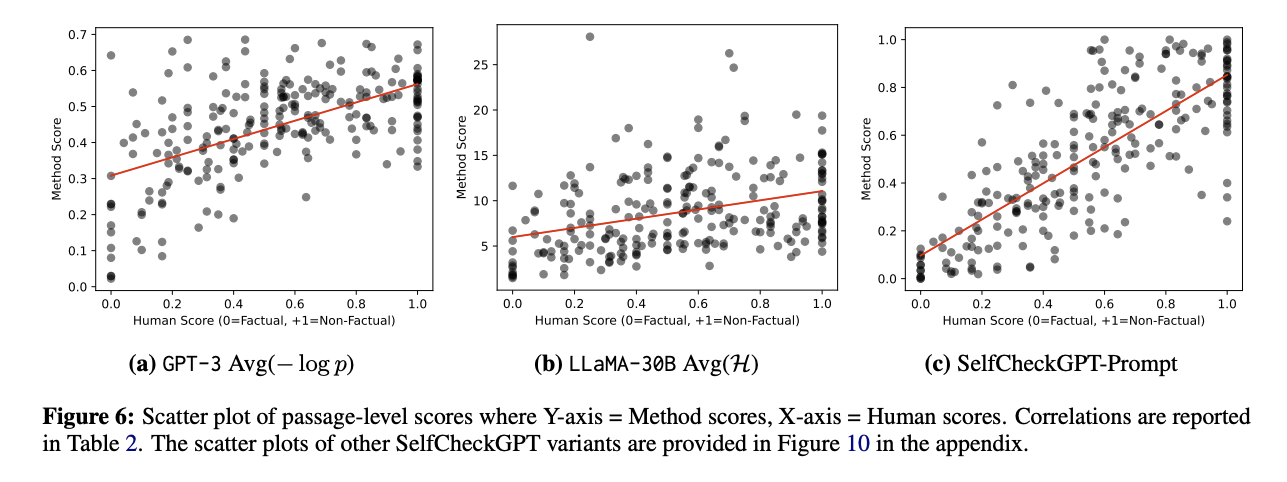
Passage-level Factuality Ranking
passage-level factuality score는 passage 내의 sentences들의 hallucination score의 평균을 구하면 된다. Table 2와 Figure 6를 보면 SelfChekcGPT는 grey-box methtod와 proxy LLM에 비해 human judgement와 상당히 높은 correlation을 가진다는 것, 즉 SelfCheckGPT가 factual / non-factual을 human align하게 잘 판단한다는 사실을 알 수 있다.
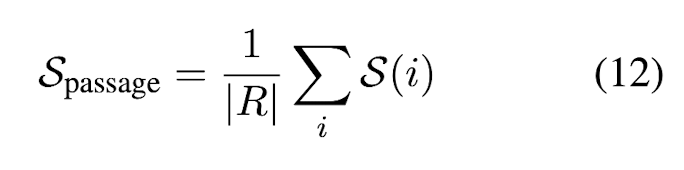
Ablation Studies
- External Knowledge (instead of SelfCheck): 즉, sampled response를 이용하여 main response의 uncertainty를 검사하기보다 그냥 external knowledge와 main response를 비교하여 그 uncertainty를 검사해봤다. external knowledge로는 WikiBio에서 first paragraph이다. 먼저, BERTScore를 보면, SelfCk이 external reference를 활용했을 때와 비슷한 성능을 보인다. 또, n-gram은 아마 n-gram model을 N sampled responses가 아닌 reference data로만 훈련시켰기에 성능이 크게 떨어진 것으로 보인다. 마지막으로, NLI의 경우 reference를 이용했을 때 성능이 상당히 향상된 것을 볼 수 있다. 그럼에도 불구하고 external database는 항상 활용할 수 있는 것이 아니라는 한계가 존재하기에~ SelfCheck이 그 점을 고려했을 때는 더 유용할 수 있다.
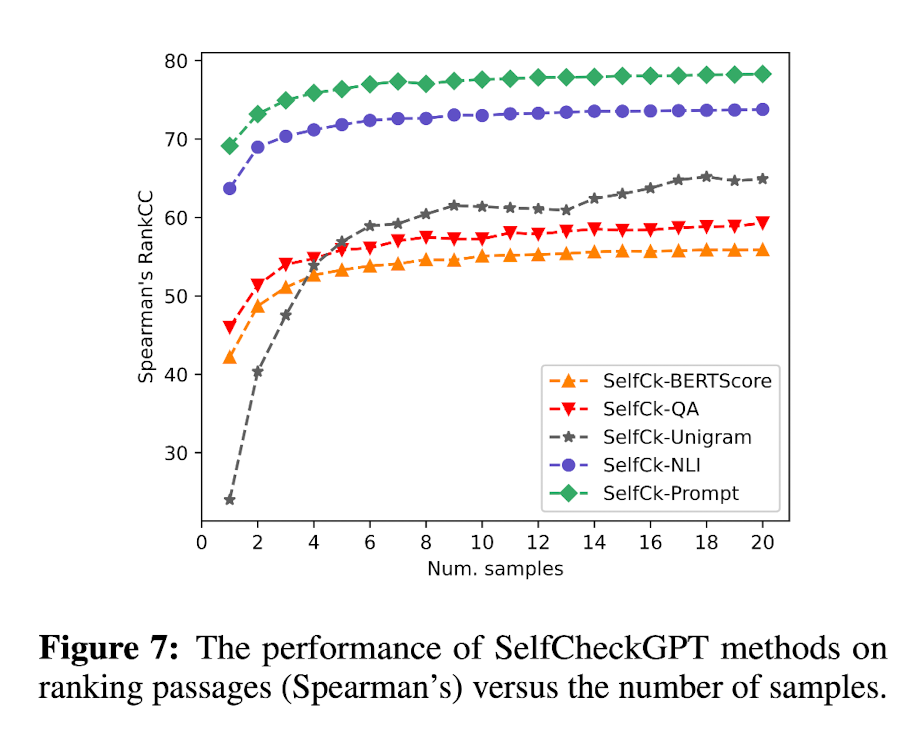
- The impact of the Number of Samples: sample response의 수가 늘어나면 확실히 성능이 좋아지긴 하지만 그만큼 cost도 많이 든다... 특히 n-gram의 경우 성능이 많이 높아지기까지 많은 수의 sample responses가 필요했ㄷ.
Conclusion
본 논문은 SelfCheckGPT를 black-box which is only text output is available and zero-source (no external database) hallucination detection approach로 소개한다. SelfCheckGPT는 크게 5가지 방법론으로 설명될 수 있고 grey-box baseline의 성능을 능가한다. sentence-level의 hallucination detection도 가능하고, 이를 이용해 더 나아가 trusthworthy passage ranking도 세울 수 있다.