📚 Paper
https://arxiv.org/pdf/2307.01379
Abstract
본 논문은 linguisitic redundancy, 즉 오직 몇몇 keyword만으로 sentence의 essence를 전달할 수 있다는 사실을 이용한다. UQ를 할 때 이런 inequality를 고려하지 않은 채 평가하는데, 이는 semantically limited token (irrelevant components)들이 semantically significant token (relevant components)과 동일한 가중치 혹은 과도한 가중치로 UQ에 반영된다는 것이다.
SAR (Shifting Attention to Relevance)는 UQ할 때 attention을 more relevant component (token-level과 sentence-level)으로 옮기는 것이 UQ에 도움이 된다는 방법론이다.

Introduction
UQ (Uncertainty Quantification)는 'LLM을 믿을 수 있는가?' 라는 질문에 대답할 수 있는 가장 dominant한 approach이다. (UQ의 중요성) 그러나, NLP에서의 UQ는 LLM의 essentially limitless solution space라는 free-form 특성이 있다. 이 때문에 defined labels where solution space is constrained가 golden answer인 다른 분야에 비해 UQ에서 어려움이 있다. (aleatoric uncertainty. e.g., Paris is the capital of France와 The capital of France is Paris는 같은 의미의 문장이지만 form이 다르기 때문에 둘 중 어떤 것을 generate해야 하는지 uncertain하다고 인식한다.)
"tokens are created unequally in presenting semantics". 즉, 각 토큰의 semantic 중요도가 다르기 때문에 UQ를 할 때도 그 영향치를 다르게 설정해야 한다는 것이다. (기존의 방법은 그러지 않았음.) 예를 들어, 모델의 generation이 "density of an object"일 때, "density"가 "of", "an", "object" 보다 semantics를 represent하는 데 있어 더 relevant하다. 전자를 relevant token, 후자를 irrelevant token이라고 한다.
어떤 text에서 semantically 더 중요한 토큰 (relevant token)과 덜 중요한 토큰 (irrelevant token)이 있다는 것은 알겠다. 그렇다면, relevant token이 irrelevant token보다 uncertainty quantification에 있어 더 중요한가?
이 질문에 대한 답을 찾기 위해 각 토큰 별 (+ sentence 별) 로 relevance score (토큰이 얼마나 semantical contribution을 하는지) 와 uncertainty proportion (토큰이 얼마나 uncertainty에 영향을 미치는지) 을 정량화했다.
Related Works
Uncertainty Quantification in LLMs
LLM의 output space는 infinite하기에 UQ를 하기 특히 어렵다. (+ semantic equivalent 문제. semantically align하지만 form이 다른 문제 -> 그래서 단순 text similarity 비교가 아니라 semantic 비교를 해야 한다고 주장~)
- quantify uncertainty by directly prompting the language models to answer the uncertainty with respect to their generations
- quantify consistency of generations
- calculate the accumulative predictive entropies over multiple generations
- semantic entropy proposes semantic equivalence problem. SE gathers generations sharing the same semantics into clusters and performs cluster-wise predictive entropy as the uncertainty measurement
본 논문도 multiple generations을 이용해 uncertainty metric을 구축하고자 한다.
Generative Inequality in Uncertainty Quantification
generation을 구성하는 토큰이 갖는 semantic significance는 다르지만, UQ할 때는 토큰들이 equally하게 다뤄지는 것을generative inequalities이라고 한다.
Preliminaries
Eq. (1)은 Predictive Entropy로, token-wise log-likelihood를 합친 sentence s의 entropy를 의미한다. p(s | x)가 최대화되어야 entropy는 최소화된다.

Token-Level Generative Inequality
given prompt x와 sentence s consists of N tokens = {z1, z2....zi....zN}이 있다.
- relevance: zi가 s의 semantic information을 얼만큼 contain하고 있는지이다. relevance는 Eq. (2)와 같이 s와 s에서 zi를 뺀 것의 semantic similarity를 계산함으로써 구할 수 있다. semantic similarity measurement g( , )로 Cross-Encoder를 사용했다. Cross-Encoder는 두 개의 문장을 입력으로 넣어 함께 결합한 상태로 encoding한다. BERT의 마지막 layer를 classifier로 두어 두 문장의 similarity 정도를 0에서 1 사이의 값으로 출력한다. RT가 클수록 zi가 s에서 빠졌을 때 문장 의미 차이가 크다는 뜻이므로 zi가 relevant함으로 의미한다.


- Uncertainty Proportion: zi가 uncertainty에 commit (영향을 미치는) 하는 정도이다. 전체 Predictive Entropy에서 zi의 token-wise entropy가 차지하는 비율을 이용해 간단하게 계산한다. UPT가 크다는 것은 p가 그만큼 낮고, 전체 uncertainty (PE)에 크게 기여한다는 것을 의미한다.

Sentence-Level Generative Inequality
sentence-level에서도 generative inequality가 발생할 수 있다.
- relevance: 주어진 sentence si에 대해 나머지 sentence와의 relevance 계산한 것. 다른 문장들과의 consistency가 높을수록 더 relevant하다는 개념 이용. 비교 sentence의 generation probability도 반영해준다.

- uncertainty proportion: token-level과 비슷하게 모든 sentence의 predictive entropies에서 각 sentence의 PE가 차지하는 비율로 계산한다. sentence si가 uncertainty 계산에 미치는 영향이다.

Analytical Insights
relevance와 uncertainty proportion을 이용해서 "relevant token / sentence가 UQ에 있어 더 중요한가?"함을 보일 수 있다.
CoQA dataset과 OPT-13b을 사용하고 # of the generations K = 10으로 설정한다. Figure 2를 보면, token-level relevance에서 대부분의 token들이 irrelevant함을 알 수 있다. 마찬가지로 sentence-level relevance에서도 irrelevant sentences들이 상당히 존재한다. 자, 이제 linguistic redundancy가 증명됐다.
이제 relevance와 UQ의 상관관계를 알아보자. relevance score를 기준으로 token과 sentence를 각각 10개의 bin으로 나눈 뒤, 각각의 bin 안에 있는 데이터들의 uncertainty proportion을 sum한다. (average하면 irrelevant component의 uncertainty proportion과 relevant component의 uncertainty proportion의 영향력이 offset될 수 있으므로) Figure 3을 보면, relevance가 높아질수록 sum of uncertainty proportion이 작아진다는 것을 알 수 있다. 즉, irrelevant tokens / sentences은 semantic으로는 중요하지 않으면서도 higher UQ를 만드는 데 큰 영향을 미치기 때문에, 이는 accurate UQ를 하기 어렵게 한다.
Figure 2와 Figure 3를 통해 generative inequality (semantic하게 중요하지 않은 토큰이 UQ에는 큰 영향을 미치는 것)을 확인했고, 이를 해결하기 위해 Shifting Attention to Relevance (SAR)을 고안한다.


Shifting Attention to Relevance
Notations
- prompt: x
- Nj tokens for each sentence sj which in S (1 <= j <= K)
Relevance Discovery and Shifting
SAR은 각 token / sentence의 relevance를 계산한 뒤 UQ attention을 more relevant component로 옮김으로써 generative inequalities를 해결한다.
- Token-Level Shifitng: Eq. (6)은 sentence sj의 i번째 토큰 zi의 relevance이다. Eq. (2)를 이용해 계산한 sj의 모든 토큰들의 relevance에서 i번째 토큰의 relevance 비율을 구하면 된다. 이런 normalization을 하는 이유는, sentence 내 토큰들을 comparable하게 만들어주기 위해, 또 length-normalization 효과를 주기 위해서이다. 그 다음, 각각의 normalized relevance를 -log probability에 곱해줌으로써 token들 사이의 attention (weight)를 re-assign해준다. re-weighted된 token-wise entropy를 더해 token-shifted predictive entropy Eq. (8)을 계산한다. 이런 식으로, 하나의 sentence 내에서 more relevant한 토큰이 UQ (PE)에 더 큰 영향을 미치도록 할 수 있다.



- Sentence-Level Shifting: high relevant sentence에게는 sentence relevance를 더해줌으로써 uncertainty를 낮춰준다. t는 temperature used to control the scale of shifting이다. Eq. (10)은 sentence-level에서 attention shifting to relevance가 일어난 것이다. (더 consistent한 문장들의 uncertainty를 줄임.) Eq. (9)는 semantically consistent하면 uncertainty를 줄였다는 점에서 SE (Semantic Entropy)와 비슷하지만 SAR이 long sentence에 대해 더 좋은 성능을 보인다.


Overall Measurement
token-level shifting과 sentence-level shifting의 목적은 다르다. token-level shifting은 irrelevant token이 애초에 UQ (PE)에 영향을 거의 미치지 못하도록 낮은 relevance를 곱해줌으로써 값을 죽이고, relevant token의 UQ 계산에 대한 영향력을 크게 한 것이다. sentence-level shifting은 multiple sentences 중 consistency를 보이는 문장들의 uncertainty를 그만큼 낮춘다. 즉, SAR을 이용하면 generative inequality에서 irrelevant token의 UQ에 대한 영향력을 죽이고 (token-level shifting) relevant token을 위주로 계산된 uncertainty에 sentence-level shifting도 해줌으로써 beneficial UQ를 할 수 있는 것이다.
token-level shifting과 sentence-level shifting을 합칠 수 있다. Eq. (9)의 p(s_j|x)와 p(s_k|x)를 각각 아래와 같이 바꿔줘 Eq. (11)을 유도할 수 있다. token-level & sentence-level shifted predictive entropy of K sentences는 Eq. (12)와 같다.



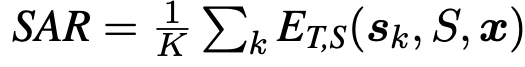

Empirical Evaluations
Experimental Settings
- Baselines: Lexical Similarity (overlapping of vocabularies between two sentences), Semantic Entropy (after form semantically-equivalent clusters, compute cluster-wise entropy to measure uncertainty), Predictive Entropy (PE(s, x) = Eq. (1)), Length-normalized Predictive Entropy (divide Predictive Entropy of sentence sj with length of N)

- Models: off-the-shelf LLMs
- Decoding:
- use greedy search (most likely generation) when compare with ground-truth when labeling whether model's generation is correct
- use multinominal sampling (sample tokens from fixed probability, do_sample = True) when generate K generations
- Datasets: 5 free-form question-answering datasets: CoQA, TriviaQA, SciQ, MedQA, MedMCQA
- Correctness Metrics: Rouge-L, sentence similarity -> if Rouge-L between ground-truth answer and most likely generation > 0.5, then that generation of LLM to given prompt x is considered to be correct
- Evaluation Metric: UQ는 LLM이 답변의 correctness를 잘 예측했는지 (0/1)를 통해 평가된다. AUROC를 통해 SAR + other baselines의 UQ performance를 평가한다.
UQ for pre-trained LLMs
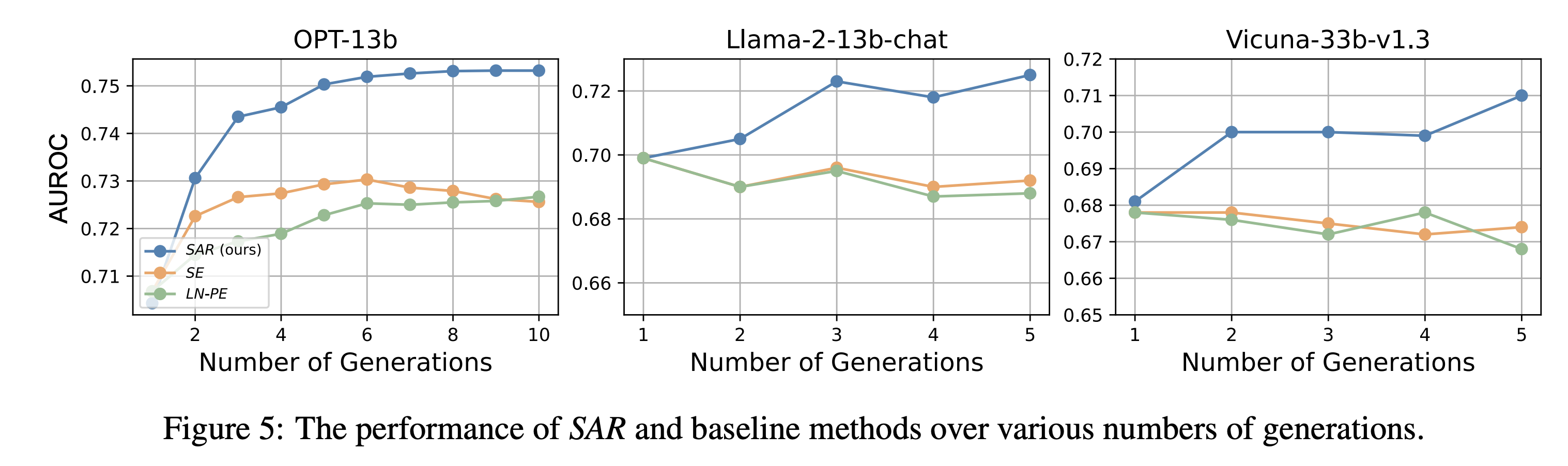
Figure 4의 SAR을 통해 TokenSAR와 SentSAR이 합쳐져 0.748 AUROC라는 synergy 효과를 낸 것을 확인할 수 있다. SAR은 기존의 SOTA metric을 outperform하는 성능을 보여줬다.

Ablation Studies
- number of generations: # of the generations K = 5일 때 0.750 AUROC를 기록하며 좋은 성능을 보였다.
- sensitivity to correctness metrics: threshold가 클수록 correctness 기준은 더 harsh해지고 UQ의 성능도 이에 영향을 받는다. 그러나 SAR은 correctness threshold의 변화에도 outperformance를 보이는 것을 확인할 수 있다.
- Efficiency Comparison: Tabel 3를 보면 sentSAR의 Time이 타 baseline에 비해 훨씬 효율적임을 알 수 있다.